Innovation Hub





Get all our Latest Research & Insights
Explore our glossary to get clear, practical definitions of the terms shaping AI security, governance, and risk management.




Videos
July 22, 2026
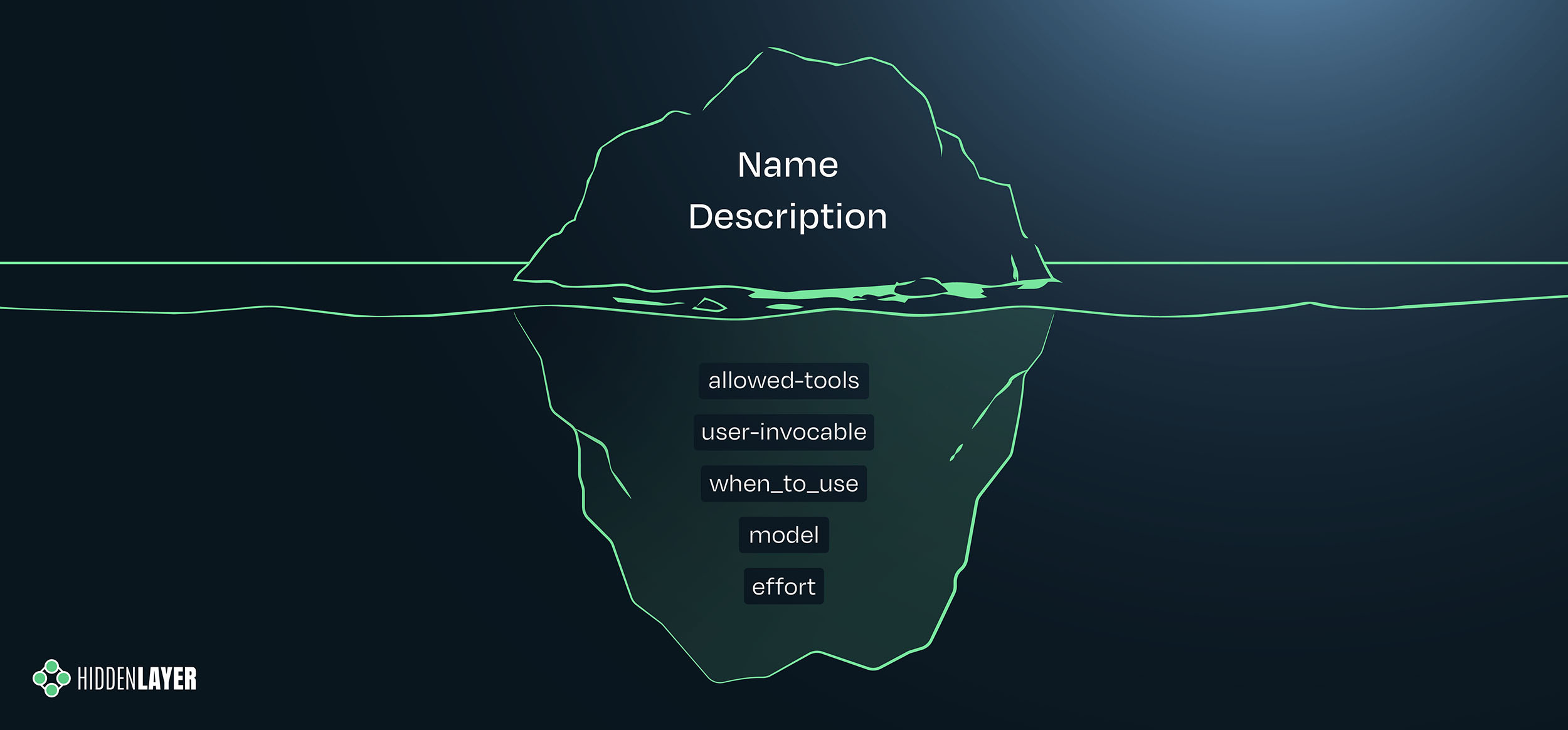
Coding Agents, Hooks & Harnesses: Securing the Next Generation of AI Agents
The biggest security risk in a coding agent usually isn't the model - it's the harness around it. HiddenLayer researchers Kieran Evans, Kenneth Yeung, and Kasimir Schulz walk through why the layers wrapping an agent (Claude Code, Cursor, Codex, and the tools, skills, and orchestration around them) have become the real attack surface - and why, in many modern agents, you no longer need a prompt injection at all. If your instructions land in a path the model already trusts, it just follows them.
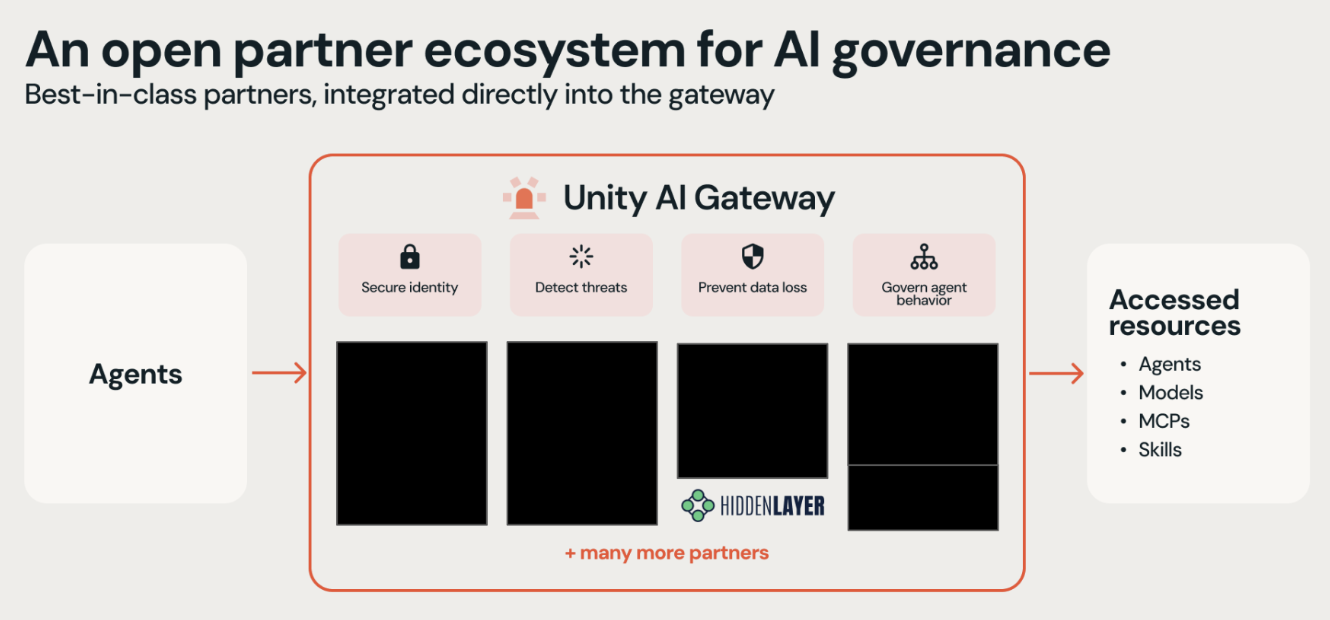
HiddenLayer Webinar: Operationalizing AI Governance: Managing Risk in Autonomous AI Systems
HiddenLayer Webinar: 2026 AI Threat Landscape Report
HiddenLayer Webinar: Offensive and Defensive Security for Agentic AI
HiddenLayer Webinar: How to Build Secure AI Agents
Report and Guides



HiddenLayer AI Security Research Advisory
Post-Authentication RCE via update_collection
Any authenticated user with UPDATE_COLLECTION permission can achieve remote code execution by updating a collection's embedding function to reference a malicious HuggingFace model with trust_remote_code: true. The update_collection endpoint uses the same build_from_config() code path as CVE-2026-45829. Authentication runs before model loading, so this is not a pre-authentication issue, but the model instantiation itself is unguarded.
V1 API Tenant Isolation Bypass via Null Tenant/Database Context
All V1 collection-level endpoints pass None for tenant and database to the authorization layer, making tenant-scoped access control impossible through V1, regardless of which authorization provider is configured. V1 cannot be disabled. Combined with CVE-2026-45830, any authenticated user has unrestricted read/write access to any collection by UUID through V1 endpoints.
RBAC Authorization Bypass: Resource Context Ignored
ChromaDB's SimpleRBACAuthorizationProvider, the only built-in RBAC provider and the one used in all official documentation examples, evaluates whether a user holds a given permission but never checks which tenant, database, or collection that permission applies to. A user configured with read access to a specific tenant can read from any tenant. A user with write access can modify data across all tenants.
Cross-Tenant Data Access via IDOR in Collection Lookup
The same vulnerability as CVE-2026-45830 is present in the Rust codebase. Any authenticated user with a valid collection UUID can read, write, update, or delete data in any tenant's collection regardless of which tenant they belong to. ChromaDB's collection lookup skips the tenant and database filter when a UUID is provided.
.avif)
In the News



Stay Ahead of AI Security Risks
Get research-driven insights, emerging threat analysis, and practical guidance on securing AI systems—delivered to your inbox.
Thanks for your message!
We will reach back to you as soon as possible.