DeepSeek-R1 Architecture
March 25, 2025





Introduction
In January, DeepSeek made waves with the release of their R1 model. Multiple write-ups quickly followed, including one from our team, discussing the security implications of its sudden adoption. Our position was clear: hold off on deployment until proper vetting has been completed.
But what if someone didn’t wait?
This blog answers that question: How can you tell if DeepSeek-R1 has been deployed in your environment without approval? We walk through a practical application of our ShadowGenes methodology, which forms the basis of our ShadowLogic detection technique, to show how we fingerprinted the model based on its architecture.
DeepSeeking R1…
For our analysis, our team converted the DeepSeek-R1 model hosted on HuggingFace to the ONNX file format, enabling us to examine its computational graph. We used this to identify its unique characteristics, piece together the defining features of its architecture, and build targeted signatures.
DeepSeek-R1 and DeepSeekV3
Initial analysis revealed that DeepSeek-R1 shares its architecture with DeepSeekV3, which supports the information provided in the model’s accompanying write-up. The primary difference is that R1 was fine-tuned using Reinforcement Learning to improve reasoning and Chain-of-Thought output. Structurally, though, the two are almost identical. For this analysis, we refer to the shared architecture as R1 unless noted otherwise.
As a baseline, we ran our existing ShadowGenes signatures against the model. They picked up the expected attention mechanism and Multi-Layer Perceptron (MLP) structures. From there, we needed to go deeper to find what makes R1 uniquely identifiable.
Key Differentiator 1: More RoPE!
We observed one unusual trait: the Rotary Positional Embeddings (RoPE) structure is present in every hidden layer. That’s not something we’ve observed often when analyzing other models. Even so, there were still distinctive features within this structure in the R1 model that were not present in any other models our team has examined.
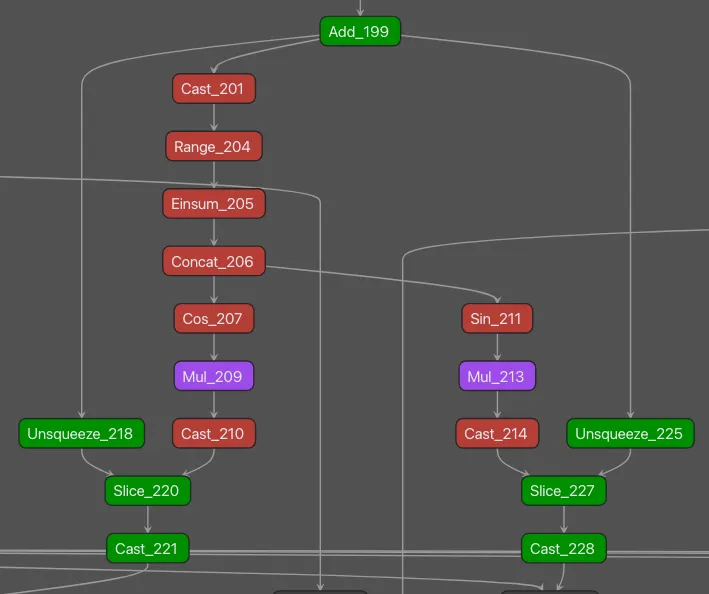
Figure 1: One key differentiating pattern observed in the DeepSeek-R1 model architecture was in the rotary embeddings section within each hidden layer.
The operators highlighted in green represent subgraphs we observed in a small number of other models when performing signature testing; those in red were seen in another DeepSeek model (DeepSeekMoE) and R1; those in purple were unique to R1.;
The subgraph shown in Figure 1 was used to build a targeted signature which fired when run against the R1 and V3 models, but not on any of those in our test set of just under fifty-thousand publicly available models.
Key Differentiator 2: More Experts
One of the key points DeepSeek highlights in its technical literature is its novel use of Mixture-of-Experts (MoE). This is, of course, something that is used in the DeepSeekMoE model, and while the theory is retained and the architecture is similar, there are differences in the graphical representation. An MoE comprises multiple ‘experts’ as part of the Multi-Layer Perceptron (MLP) shown in Figure 2.
Interesting note here: We found a subtle difference between the V3 and R1 models, in that the R1 model actually has more experts within each layer.
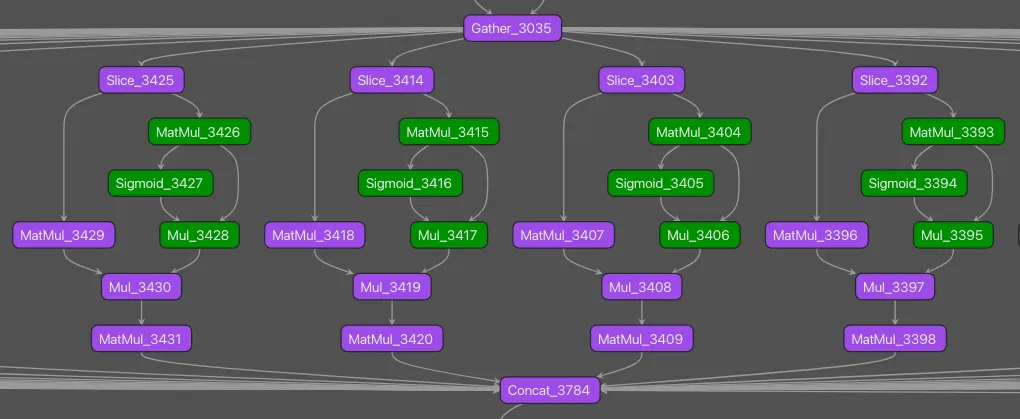
Figure 2: Another key differentiating pattern observed within the DeepSeek-R1 model architecture was the Mixture-of-Experts repeating subgraph.
The above visualization shows four experts. The operators highlighted in green are part of our pre-existing MLP signature, which - as previously mentioned - fired on this model prior to any analysis. We fleshed this signature out to include the additional operators for the MoE structure observed in R1 to hone in more acutely on the model itself. In testing, as above, this signature detected the pattern within DeepSeekV3 and DeepSeek-R1 but not in any of our near fifty-thousand test set of models.
Why This Matters
Understanding a model’s architecture isn’t just academic. It has real security implications. A key part of a model-vetting process should be to confirm whether or not the developer’s publicly distributed information about it is consistent with its architecture. ShadowGenes allows us to trace the building blocks and evolutionary steps visible within a model's architecture, which can be used to understand its genealogy. In the case of DeepSeek-R1, this level of insight makes it possible to detect unauthorized deployments inside an organization’s environment.
This capability is especially critical as open-source models become more powerful and more readily adopted. Teams eager to experiment may bypass internal review processes. With ShadowGenes and ShadowLogic, we can verify what's actually running.
Conclusion
Understanding the architecture of a model like DeepSeek is not only interesting from a researcher’s perspective, but it is vitally important because it allows us to see how new models are being built on top of pre-existing models with novel tweaks and ideas. DeepSeek-R1 is just one example of how AI models evolve and how those changes can be tracked.;
At HiddenLayer, we operate on a trust-but-verify principle. Whether you're concerned about unsanctioned model use or the potential presence of backdoors, our methodologies provide a systematic way to assess and secure your AI environments.
For a more technical deep dive, read here.
Related Research



The Next AI Supply Chain Risk: Malicious Skills in Agentic AI
Agentic AI is rapidly transforming how individuals and enterprises work, with skills emerging as a key mechanism for extending agent capabilities. However, the same flexibility that makes skills powerful also creates a new supply chain attack surface.

Inside the Prompt: How LLMs Learn Roles, Follow Instructions, and Get Exploited
Learn how LLMs use control tokens, instruction hierarchy, and prompt templates to power agentic AI systemsand how attackers exploit these same mechanisms through prompt injection and control token spoofing.

Stay Ahead of AI Security Risks
Get research-driven insights, emerging threat analysis, and practical guidance on securing AI systems—delivered to your inbox.