Learn from our AI Security Experts
Discover every model. Secure every workflow. Prevent AI attacks - without slowing innovation.

All Resources


NSPM-11 Elevates AI Security from Best Practice to National Security Requirement
On June 5, 2026, the White House released National Security Presidential Memorandum-11 (NSPM-11), establishing a framework for accelerating AI adoption across the national security enterprise. One detail stands out from a security perspective: Section 4(c) explicitly directs leaders to secure advanced AI systems, including protection against malicious distillation attacks.
Presidential directives rarely reference specific attack techniques. By naming model distillation directly, NSPM-11 acknowledges a reality security teams have been confronting for years: AI systems are now strategic assets and attack targets. Protecting those systems from theft, manipulation, and misuse is a national security requirement.
The memorandum organizes the national security enterprise around four pillars: Adoption, Adaptation, Assurance, and Accountability. While much of the discussion around NSPM-11 has focused on accelerating AI deployment, the Assurance pillar deserves equal attention. It is the foundation that enables organizations to adopt AI confidently and securely.
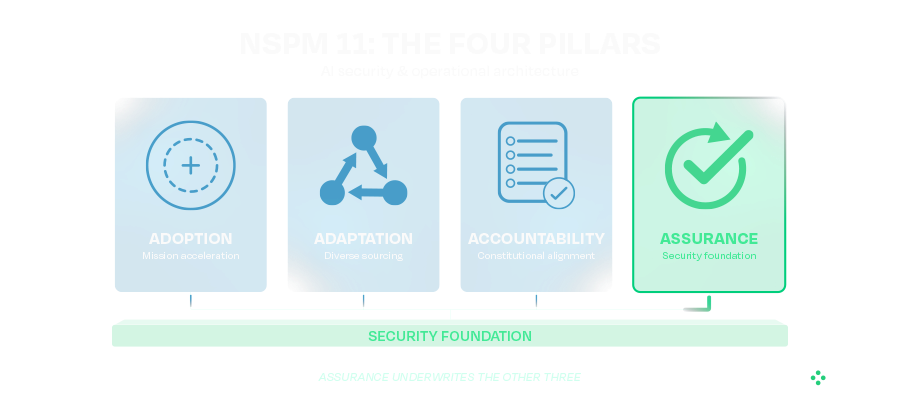
Understanding the Three AI Challenges
Discussions about AI security often blur together three distinct disciplines:
- AI for Cybersecurity: Using AI to improve security operations, threat detection, vulnerability management, and defensive capabilities.
- Responsible AI: Ensuring AI systems operate safely, ethically, and in compliance with applicable laws, policies, and governance requirements.
- AI Security: Protecting AI systems themselves from theft, manipulation, compromise, and adversarial attacks.
While these disciplines are complementary, they address different risks and require different controls.
Responsible AI programs help organizations manage governance and compliance risks, but they are not designed to identify model backdoors or model theft. AI-powered cybersecurity tools may improve detection and response capabilities, but they do not inherently protect the models themselves from attack.
AI security focuses on a different question entirely: Can an adversary manipulate, steal, poison, or otherwise compromise the model?
That distinction is central to NSPM-11's Assurance pillar and highlights why AI security has emerged as its own cybersecurity discipline.

The Significance of NSPM-11's Definitions
One of the most important aspects of NSPM-11 is how it defines AI security. The memorandum defines AI security as applying protection mechanisms across the AI technology stack to ensure the confidentiality, integrity, and availability of AI systems from design through deployment.
This aligns AI security with established cybersecurity principles while recognizing that AI introduces unique attack surfaces. The policy also broadens the concept of AI incident response to include adversarial attacks against AI systems themselves, reinforcing the need to monitor, defend, and validate AI models like any other critical technology asset.
This shift is significant because it formally recognizes AI systems as operational assets that require dedicated security controls. Threats such as prompt injection, model extraction, training data poisoning, and model backdoors are no longer theoretical concerns. They are security risks that organizations must be prepared to detect, investigate, and respond to.
Assurance Requires Independent Verification
The Assurance pillar emphasizes maintaining visibility and control over mission-critical AI systems.
NSPM-11 requires mechanisms that prevent AI systems from being materially modified without government knowledge and approval. This reflects two realities facing organizations adopting AI at scale.
First, AI systems can be intentionally manipulated. Adversaries may attempt to alter a model's behavior through tampering, poisoning, or the introduction of hidden functionality.
Second, organizations must maintain independent visibility into the AI systems they rely on. As agencies deploy models from commercial providers, open-source communities, and internal development teams, they need the ability to verify model integrity regardless of where the model originated.
This requirement naturally favors security capabilities that operate independently of any single model vendor. As the AI ecosystem becomes increasingly diverse, organizations need assurance mechanisms that can evaluate and secure AI systems consistently across different model architectures, deployment environments, and suppliers.
Equally important, those assurance mechanisms should align with established frameworks such as MITRE ATLAS, the NIST AI Risk Management Framework (AI RMF), and emerging federal AI security guidance. Aligning AI security programs with recognized frameworks enables organizations to consistently evaluate risk, validate security controls, and demonstrate assurance through transparent, repeatable methodologies.
What AI Security Looks Like in Practice
The threats addressed by NSPM-11 are not hypothetical.
HiddenLayer researchers demonstrated this challenge through ShadowLogic, a technique that embeds malicious behavior directly within a model's computational graph rather than in traditional software components.
Because these manipulations exist within the model itself, they can evade conventional malware detection approaches and persist through common model transformations. Research has demonstrated that these types of backdoors can remain dormant until triggered by specific conditions, highlighting a key challenge for AI security: many AI threats lie beyond the visibility of traditional security controls, making specialized model analysis and validation essential before deployment.
However, securing AI systems extends beyond model artifacts alone.
At deployment and runtime, organizations must contend with attacks such as prompt injection, jailbreaks, sensitive data extraction, and other adversarial techniques that target model behavior through inference interactions. Many of these risks are now well documented within industry frameworks, including the OWASP Top 10 for LLM Applications and MITRE ATLAS. These resources provide a common language for understanding AI attack techniques and reinforce the need for security controls that continuously monitor model interactions and behavior in production environments.
At the strategic level, NSPM-11 specifically calls out model distillation attacks, in which an adversary repeatedly queries a deployed model to replicate its capabilities in another system. In these cases, the attacker may never gain direct access to model weights or infrastructure. Instead, they extract value through interaction.
These threats occur at different stages of the AI lifecycle, which is why effective AI security requires a layered approach. Model integrity validation, runtime monitoring, adversarial testing, and continuous assessment each address different aspects of the attack surface.
The principle is familiar to every security practitioner: defense in depth applies to AI just as it does to traditional systems.
Why AI Security Is a Distinct Discipline
NSPM-11 reinforces why AI security has emerged as a dedicated cybersecurity discipline.
Traditional security controls remain essential, but they were not designed to identify model backdoors, detect attempts to extract models, or analyze machine learning artifacts for signs of tampering.
Addressing these risks requires capabilities focused specifically on AI systems, including:
- Model scanning and artifact analysis
- Runtime monitoring for AI-specific attacks
- Adversarial testing and AI red teaming
- Continuous validation of model integrity
- AI-focused incident response and investigation
These capabilities should operate independently of any single model provider, enabling organizations to evaluate and secure AI systems consistently across a diverse technology ecosystem.
This challenge becomes even more important within national security environments. A model can be protected by strong network controls and still be compromised before deployment if the model artifact itself contains malicious modifications. Security must therefore extend beyond infrastructure and include the AI system itself.
Additionally, many mission-critical AI deployments operate in disconnected, classified, or air-gapped environments. Security controls that require continuous communication with vendor-hosted cloud services may not be practical in these settings. Effective AI security must be able to operate within the organization's environment and security boundaries.
The Bottom Line
NSPM-11 reinforces a principle that security teams already understand: trust requires verification.
As agencies accelerate AI adoption, security leaders must evaluate not only model performance but also their ability to verify model integrity, understand model behavior under adversarial conditions, and deploy security controls that operate within mission environments.
Before deploying a model, organizations should be able to answer three fundamental questions:
- Can we verify the integrity of this model?
- Can we understand how it behaves under attack?
- Can security controls operate within our environment, including disconnected or classified networks?
NSPM-11 makes clear that AI assurance is no longer optional. As AI becomes foundational to mission execution, securing the model itself must become a foundational part of the security strategy.
The organizations that can answer these questions with confidence will be best positioned to adopt AI at scale while maintaining trust, resilience, and operational readiness.
HiddenLayer and Databricks Unity AI Gateway
What Databricks' Unity AI Gateway Announcement Signals About the Future of Enterprise AI
For the past two years, the conversation around AI has centered on possibility.
Organizations raced to identify use cases, experiment with foundation models, and understand how generative AI could transform productivity, customer experiences, and business operations. The primary question was whether AI could deliver value.
Today, that question has largely been answered. The challenge facing enterprises now is not whether to adopt AI, but how to manage it at scale.
AI Is Entering Its Operational Era
As AI becomes embedded throughout organizations, in applications, business processes, agents, and workflows, the complexity of operating these systems is growing just as quickly as the benefits they provide. Security teams are being asked to govern environments spanning multiple models, providers, development teams, and deployment architectures. At the same time, business leaders are demanding greater visibility into usage, costs, and outcomes.
This is why Databricks' latest enhancements to Unity AI Gateway are noteworthy.
While the announcement focuses on capabilities such as cost monitoring, budget controls, and policy enforcement, its broader significance lies in what it reveals about the state of enterprise AI. Organizations are moving beyond experimentation and into operationalization. They are beginning to recognize that successful AI adoption requires holistic governance.
Governance Is Becoming a Business Requirement
That shift mirrors what we've seen before with other transformative technologies. Cloud computing eventually required cloud security and cloud governance. SaaS adoption created new demands for visibility and control. AI is following a similar trajectory, but at an accelerated pace.
As AI usage expands, enterprises need to understand not only what their AI systems can do, but how those systems are being used, where risks exist, and whether appropriate controls are in place. Cost governance is one important aspect of that challenge. Security is another.
In many ways, these conversations are becoming inseparable.
Why Visibility Into AI Risk Matters
The same organizations seeking visibility into AI spending are also seeking visibility into AI risk. They want to understand where AI is deployed, which models are being used, how agents interact with business systems, and whether governance policies are being consistently enforced. They need confidence that innovation is occurring within guardrails that support security, compliance, and operational resilience..
Rather than treating governance, security, and operations as separate initiatives, enterprises are beginning to build a more comprehensive approach to AI oversight. The goal is not to slow adoption. It is to create the visibility and control necessary to scale AI responsibly.
The Expanding AI Control Plane
At HiddenLayer, we've long believed that trust is a prerequisite for AI adoption. Organizations cannot secure what they cannot see, and they cannot govern what they do not understand. As AI environments become increasingly complex, gaining visibility into AI assets, understanding risk exposure, and implementing effective controls become foundational requirements for success.
This announcement signals that the market is maturing. The conversation is shifting from experimentation to operations, from access to accountability, and from AI innovation alone to the systems required to support AI at enterprise scale.
From AI Adoption to AI Accountability
The future of AI will not be defined solely by more powerful models or more capable agents. It will be defined by how effectively organizations can manage, govern, and secure them.
Databricks' latest announcement is another step in that direction, and we are proud to be part of an ecosystem helping organizations build that future.

From Detection to Evidence: Making AI Security Actionable in Real Time
An enterprise team evaluates a third-party model before deploying it into production. During scanning, their security tooling flags a high-risk issue. Engineers now need to determine whether the finding is valid and what action to take before moving forward.
Detection Isn’t Enough: Why AI Security Needs Evidence
An enterprise team evaluates a third-party model before deploying it into production. During scanning, their security tooling flags a high-risk issue. Engineers now need to determine whether the finding is valid and what action to take before moving forward.
The problem is that the alert does not explain why it was triggered. There is no visibility into what part of the model caused it, what behavior was observed, or what the actual risk is. The team is left with two options: spend time investigating or avoid using the model altogether.
This is a common pattern, and it highlights a broader issue in AI security.
The Problem: Detection Without Context
As organizations increasingly rely on third-party and open-source models, security tools are doing what they are designed to do: generate alerts when something looks suspicious.
But alerts alone are not enough.
Without context, teams are forced into:
- manual investigation
- guesswork
- overly conservative decisions, such as replacing entire models
This slows down response, increases cost, and introduces operational friction. More importantly, it limits trust in the system itself. If teams cannot understand why something was flagged, they cannot act on it confidently.
Discovery Is Only Half the Equation
The industry is rapidly improving its ability to detect issues within models. But detection is only one part of the process.
Vulnerabilities and risks still need to be:
- understood
- validated
- prioritized
- remediated
Without clear insight into what triggered a detection, these steps become inefficient. Teams spend more time interpreting alerts than resolving them.
Detection without evidence does not reduce risk, it shifts the burden downstream.
From Alerts to Actionable Intelligence
What’s missing is not detection, but evidence.
Detection evidence provides the context needed to move from alert to action. Instead of surfacing isolated findings, it exposes:
- the exact function calls associated with a detection
- the arguments passed into those functions
- the configurations that indicate anomalous or malicious behavior
This level of detail changes how teams operate.
Rather than asking:
“Is this alert real?”
Teams can ask:
“What happened, where did it happen, and how do we fix it?”
Why Evidence Changes the Workflow
When detection is paired with evidence, several things happen:
- Triage accelerates
Teams can quickly understand the root cause of an alert without manual deep dives - Remediation becomes precise
Instead of replacing or reworking entire models, teams can target specific functions or configurations - Operational cost decreases
Less time is spent investigating and revalidating models - Confidence increases
Teams can safely deploy and maintain models with a clear understanding of associated risks
This is especially important for organizations adopting third-party or open-source models, where visibility into internal behavior is often limited.
The Shift: From Detection to Evidence
AI security is evolving from:
- detection → alerts
to:
- detection → evidence → action
As models are increasingly adopted across enterprise environments, the need for this shift becomes more pronounced. The question is no longer just whether something is risky, but whether teams can understand and resolve that risk before deployment.
Conclusion
Detection remains a critical foundation, but it is no longer sufficient on its own.
As organizations evaluate models before deploying them into production, security teams need more than signals. They need context. The ability to see how a detection was triggered, where it occurred, and what it means in practice is what enables effective remediation.
In this environment, the organizations that succeed will not be those that generate the most alerts, but those that can turn those alerts into actionable insight, ensuring that risk is identified, understood, and resolved before models reach production.

The Threat Congress Just Saw Isn’t New. What Matters Is How You Defend Against It.
An enterprise team evaluates a third-party model before deploying it into production. During scanning, their security tooling flags a high-risk issue. Engineers now need to determine whether the finding is valid and what action to take before moving forward.
When safety behavior can be removed from a model entirely, the perimeter of AI security fundamentally shifts.
Last week, researchers from the Department of Homeland Security briefed the U.S. House of Representatives using purpose-modified large language models. These systems had their built-in safety mechanisms removed, and the results were immediate. Within seconds, they generated detailed guidance for mass-casualty scenarios, targeting public figures, and other activities that commercial models are explicitly designed to refuse.
Public coverage has treated this as a turning point. For practitioners, it is the public surfacing of a threat class that has been actively researched and exploited for some time.For organizations deploying AI in high-stakes environments, the demonstration aligns with known attack methods rather than introducing a new one.
What has changed is the level of visibility. The briefing brought a class of threats into a broader conversation, which now raises a more important question: what does it take to defend against them?

Censored vs. Abliterated Models: A Distinction That Changes the Problem
At the center of the DHS demonstration is a distinction that still isn’t widely understood outside of technical circles.
Most commercial AI systems today are censored models, meaning they have been aligned to refuse harmful or disallowed requests. That refusal behavior is what users experience as “safety.”
An abliterated model has had that refusal behavior deliberately removed.
This is fundamentally different from a jailbreak. Jailbreaks operate at the prompt level and attempt to coax a model into bypassing safeguards. Their success varies, and they are often mitigated over time. The operational difference matters. Jailbreaks succeed intermittently and degrade as model providers patch them. Abliteration succeeds reliably on every attempt and is permanent in the weights of the distributed model. From a defender's standpoint, those are different problems.
Abliteration occurs at the weight level. Research has shown that refusal behavior exists as a direction in latent space; removing that direction eliminates the model’s ability to refuse. The result is consistent, persistent behavior that cannot be corrected with prompts, system instructions, or downstream guardrails. From an operational standpoint, this changes where defense must happen.
Once a model has been modified in this way, there is no reliable runtime mechanism to restore the missing safety behavior. The model itself has been altered. These modified models can also be distributed through common channels, such as open-source repositories, embedded applications, or internal deployment pipelines, making them difficult to distinguish without targeted inspection.
Why Traditional Security Approaches Fall Short
A common question that follows is whether existing cybersecurity controls already address this type of risk.
Traditional security tools are designed around code, binaries, and network activity. AI models do not behave like conventional software. They consist of weights and computation graphs rather than executable logic in the traditional sense.
When a model is modified, whether through weight manipulation or graph-level backdoors, the changes often fall outside the visibility of existing tools. The model loads correctly, passes integrity checks, and continues to operate as expected within the application. At the same time, its behavior may have fundamentally changed. This disconnect highlights a gap between what traditional security controls can observe and how AI systems actually function.

Securing the AI Supply Chain
The Congressional briefing showcased one technique. The broader supply-chain attack surface includes several others that defenders must account for in parallel. Addressing that gap starts before a model is ever deployed. A defensible approach to AI security treats models as supply-chain artifacts that must be verified before use. Static analysis plays a critical role at this stage, allowing organizations to evaluate models without executing them.
HiddenLayer’s AI Security Platform operates at build time and ingest, identifying signs of compromise before models reach production environments. The platform’s Supply Chain module is designed to function across deployment contexts, including airgapped and sensitive environments.
The analysis focuses on detecting practical attack methods, including graph-level backdoors that activate under specific conditions (such as ShadowLogic), control-vector injections that introduce refusal ablation through the computational graph, embedded malware, serialization exploits, and poisoning indicators. Static analysis does not address every threat class: weight-level abliteration of the kind demonstrated to Congress modifies weights without altering the graph, and is best mitigated through provenance controls and runtime detection. This is exactly why supply chain security and runtime protection must operate together.
Each scan produces an AI Bill of Materials, providing a verifiable record of model integrity. For organizations operating under governance frameworks, this creates a clear mechanism for validating AI systems rather than relying on assumptions.
Integrating these checks into CI/CD pipelines ensures that model verification becomes a standard part of the deployment process.
Securing the Runtime: Where Attacks Play Out

Supply chain security addresses one part of the problem, but runtime behavior introduces additional risk.
As AI systems evolve toward agentic architectures, models interact with external tools, data sources, and user inputs in increasingly complex ways. This expands the attack surface and creates new opportunities for manipulation. And as agentic systems chain models together, a single compromised component can propagate through the pipeline. We will cover that cascading-trust failure mode in a follow-up.
Runtime protection provides a layer of defense at this stage. HiddenLayer’s AI Runtime Security module operates between applications and models, inspecting prompts and responses in real time. Detection is handled by purpose-built deterministic classifiers that sit outside the model's inference path entirely. This separation is deliberate. A guardrail that is itself an LLM inherits the failure modes of the system it is protecting. The same prompt-engineering, the same indirect injection, and in some cases the same weight-level modification techniques all apply. Defending an LLM with another LLM is a category error. AIDR uses purpose-built deterministic classifiers that sit outside the inference path entirely, so adversarial inputs that defeat the protected model do not also defeat the detector.
In practice, this includes detecting prompt injection attempts, identifying jailbreaks and indirect attacks, preventing data leakage, and blocking malicious outputs. For agentic systems, it also provides session-level visibility, tool-call inspection, and enforcement actions during execution.
The Broader Takeaway: Safety and Security Are Not the Same

The DHS demonstration highlights a broader issue in how AI risk is often discussed. Safety focuses on guiding models to behave appropriately under expected conditions. Security focuses on maintaining that behavior when conditions are adversarial or uncontrolled.
Most modern AI development has prioritized safety, which is necessary but not sufficient for real-world deployment. Systems operating in adversarial environments require both.
What Comes Next
Organizations deploying AI, particularly in high-impact environments, need to account for these risks as part of their standard operating model. That begins with verifying models before deployment and continues with monitoring and enforcing behavior at runtime. It also requires using controls that do not depend on the model itself to ensure safety.
The techniques demonstrated to Congress have been developing for some time, and the defensive approaches are already available. The priority now is applying them in practice as AI adoption continues to scale.
HiddenLayer protects predictive, generative, and agentic AI applications across the entire AI lifecycle, from discovery and AI supply chain security to attack simulation and runtime protection. Backed by patented technology and industry-leading adversarial AI research, our platform is purpose-built to defend AI systems against evolving threats. HiddenLayer protects intellectual property, helps ensure regulatory compliance, and enables organizations to safely adopt and scale AI with confidence. Learn more at hiddenlayer.com.

Claude Mythos: AI Security Gaps Beyond Vulnerability Discovery
An enterprise team evaluates a third-party model before deploying it into production. During scanning, their security tooling flags a high-risk issue. Engineers now need to determine whether the finding is valid and what action to take before moving forward.
Anthropic’s announcement of Claude Mythos and the launch of Project Glasswing may mark a significant inflection point in the evolution of AI systems. Unlike previous model releases, this one was defined as much by what was not done as what was. According to Anthropic and early reporting, the company has reportedly developed a model that it claims is capable of autonomously discovering and exploiting vulnerabilities across operational systems, and has chosen not to release it publicly.
That decision reflects a recognition that AI systems are evolving beyond tools that simply need to be secured and are beginning to play a more active role in shaping security outcomes. They are increasingly described as capable of performing tasks traditionally carried out by security researchers, but doing so at scale and with autonomy introduces new risks that require visibility, oversight, and control. It also raises broader questions about how these systems are governed over time, particularly as access expands and more capable variants may be introduced into wider environments. As these systems take on more active roles, the challenge shifts from securing the model itself to understanding and governing how it behaves in practice.
In this post, we examine what Mythos may represent, why its restricted release matters, and what it signals for organizations deploying or securing AI systems, including how these reported capabilities could reshape vulnerability management processes and the role of human expertise within them. We also explore what this shift reveals about the limits of alignment as a security strategy, the emerging risks across the AI supply chain, and the growing need to secure AI systems operating with increasing autonomy.
What Anthropic Built and Why It Matters
Claude Mythos is positioned as a frontier, general-purpose model with advanced capabilities in software engineering and cybersecurity. Anthropic’s own materials indicate that models at this level can potentially “surpass all but the most skilled” human experts at identifying and exploiting software vulnerabilities, reflecting a meaningful shift in coding and security capabilities.
According to public reporting and Anthropic’s own materials, the model is being described as being able to:
- Identify previously unknown vulnerabilities, including long-standing issues missed by traditional tooling
- Chain and combine exploits across systems
- Autonomously identify and exploit vulnerabilities with minimal human input
These are not incremental improvements. The reported performance gap between Mythos and prior models suggests a shift from “AI-assisted security” to AI-driven vulnerability discovery and exploitation. Importantly, these capabilities may extend beyond isolated analysis to interact with systems, tools, and environments, making their behavior and execution context increasingly relevant from a security standpoint.
Anthropic’s response is equally notable. Rather than releasing Mythos broadly, they have limited access to a small group of large technology companies, security vendors, and organizations that maintain critical software infrastructure through Project Glasswing, enabling them to use the model to identify and remediate vulnerabilities across both first-party and open-source systems. The stated goal is to give defenders a head start before similar capabilities become widely accessible. This reflects a shift toward treating advanced model capabilities as security-sensitive.
As these capabilities are put into practice through initiatives like Project Glasswing, the focus will naturally shift from what these models can discover to how organizations operationalize that discovery, ensuring vulnerabilities are not only identified but effectively prioritized, shared, and remediated. This also introduces a need to understand how AI systems operate as they carry out these tasks, particularly as they move beyond analysis into action.
AI Systems Are Now Part of the Attack Surface
Even if Mythos itself is not publicly available, the trajectory is clear. Models with similar capabilities will emerge, whether through competing AI research organizations, open-source efforts, or adversarial adaptation.
This means organizations should assume that AI-generated attacks will become increasingly capable, faster, and harder to detect. AI is no longer just part of the system to be secured; it is increasingly part of the attack surface itself. As a result, security approaches must extend beyond protecting systems from external inputs to understanding how AI systems themselves behave within those environments.
Alignment Is Not a Security Control
This also exposes a deeper assumption that underpins many current approaches to AI security: that the model itself can be trusted to behave as intended. In practice, this assumption does not hold. Alignment techniques, methods used to guide a model’s behavior toward intended goals, safety constraints, and human-defined rules, prompting strategies, and safety tuning can reduce risk, but they do not eliminate it. Models remain probabilistic systems that can be influenced, manipulated, or fail in unexpected ways. As systems like Mythos are expected to take on more active roles in identifying and exploiting vulnerabilities, the question is no longer just what the model can do, but how its behavior is verified and controlled.
This becomes especially important as access to Mythos capabilities may expand over time, whether through broader releases or derivative systems. As exposure increases, so does the need for continuous evaluation of model behavior and risk. Security cannot rely solely on the model’s internal reasoning or intended alignment; it must operate independently, with external mechanisms that provide visibility into actions and enforce constraints regardless of how the model behaves.
The AI Supply Chain Risk
At the same time, the introduction of initiatives like Project Glasswing highlights a dimension that is often overlooked in discussions of AI-driven security: the integrity of the AI supply chain itself. As organizations begin to collaborate, share findings, and potentially contribute fixes across ecosystems, the trustworthiness of those contributions becomes critical. If a model or pipeline within that ecosystem is compromised, the downstream impact could extend far beyond a single organization. HiddenLayer’s 2025 Threat Report highlights vulnerabilities within the AI supply chain as a key attack vector, driven by dependencies on third-party datasets, APIs, labeling tools, and cloud environments, with service providers emerging as one of the most common sources of AI-related breaches.
In this context, the risk is not just exposure, but propagation. A poisoned model contributing flawed or malicious “fixes” to widely used systems represents a fundamentally different kind of risk that is not addressed by traditional vulnerability management alone. This shifts the focus from individual model performance to the security and provenance of the entire pipeline through which models, outputs, and updates are distributed.
Agentic AI and the Next Security Frontier
These risks are further amplified as AI systems become more autonomous and begin to operate in agentic contexts. Models capable of chaining actions, interacting with tools, and executing tasks across environments introduce a new class of security challenges that extend beyond prompts or static policy controls. As autonomy increases, so does the importance of understanding what actions are being taken in real time, how decisions are made, and what downstream effects those actions produce.
As a result, security must evolve from static safeguards to continuous monitoring and control of execution. Systems like Mythos illustrate not just a step change in capability, but the emergence of a new operational reality where visibility into runtime behavior and the ability to intervene becomes essential to managing risk at scale. At the same time, increased capability and visibility raise a parallel challenge: how organizations handle the volume and impact of what these systems uncover.
Discovery Is Only Half the Equation
Finding vulnerabilities at scale is valuable, but discovery alone does not improve security. Vulnerabilities must be:
- validated
- prioritized
- remediated
In practice, this is where the process becomes most complex. Discovery is only the starting point. The real work begins with disclosure: identifying the right owners, communicating findings, supporting investigation, and ultimately enabling fixes to be deployed safely. This process is often fragmented, time-consuming, and difficult to scale.
Anthropic’s approach, pairing capability with coordinated disclosure and patching through Project Glasswing, reflects an understanding of this challenge. Detection without mitigation does not reduce risk, and increasing the volume of findings without addressing downstream bottlenecks can create more pressure than progress.
While models like Mythos may accelerate discovery, the processes that follow: triage, prioritization, coordination, and patching remain largely human-driven and operationally constrained. Simply going faster at identifying vulnerabilities is not sufficient. The industry will likely need new processes and methodologies to handle this volume effectively.
Over time, this may evolve toward more automated defense models, where vulnerabilities are not only detected but also validated, prioritized, and remediated in a more continuous and coordinated way. But today, that end-to-end capability remains incomplete.
The Human Dimension
It is also worth acknowledging the human dimension of this shift. For many security researchers, the capabilities described in early reporting on models like Mythos raise understandable concerns about the future of their role. While these capabilities have not yet been widely validated in open environments, they point to a direction that is difficult to ignore.
When systems begin performing tasks traditionally associated with vulnerability discovery, it can create uncertainty about where human expertise fits in.
However, the challenges outlined above suggest a more nuanced reality. Discovery is only one part of the security lifecycle, and many of the most difficult problems, like contextual risk assessment, coordinated disclosure, prioritization, and safe remediation, remain deeply human.
As the volume and speed of vulnerability discovery increase, the role of the security researcher is likely to evolve rather than diminish. Expertise will be needed not just to identify vulnerabilities, but to:
- interpret their impact
- prioritize response
- guide remediation strategies
- and oversee increasingly automated systems
In this sense, AI does not eliminate the need for human expertise; it shifts where that expertise is applied. The organizations that navigate this transition effectively will be those that combine automated discovery with human judgment, ensuring that speed is matched with context, and scale with control.
Defenders Must Match the Pace of Discovery
The more consequential shift is not that AI can find vulnerabilities, but how quickly it can do so.
As discovery accelerates, so must:
- remediation timelines
- patch deployment
- coordination across ecosystems
Open-source contributors and enterprise teams alike will need to operate at a pace that keeps up with automated discovery. If defenders cannot match that speed, the advantage shifts to adversaries who will inevitably gain access to similar models and capabilities. At the same time, increased speed reduces the window for direct human intervention, reinforcing the need for mechanisms that can observe and control actions as they occur, while allowing human expertise to focus on higher-level oversight and decision making.
Not All Vulnerabilities Matter Equally
A critical nuance is often overlooked: not all vulnerabilities carry the same risk. Some are theoretical, some are difficult to exploit, and others have immediate, high-impact consequences, and how they are evaluated can vary significantly across industries.
Organizations need to move beyond volume-based thinking and focus on impact-based prioritization. Risk is contextual and depends on:
- industry-specific factors
- environment-specific configurations
- internal architecture and controls
The ability to determine which vulnerabilities matter, and to act accordingly, is as important as the ability to find them.
Conclusion
Claude Mythos and Project Glasswing point to a broader shift in how AI may impact vulnerability discovery and remediation. While the full extent of these capabilities is still emerging, they suggest a future where the speed and scale of discovery could increase significantly, placing new pressure on how organizations respond.
In that context, security may increasingly be shaped not just by the ability to find vulnerabilities, nor even to fix them in isolation, but by the ability to continuously prioritize, remediate, and keep pace with ongoing discovery, while focusing on what matters most. This will require moving beyond assumptions that aligned models can be inherently trusted, toward approaches that continuously validate behavior, enforce boundaries, and operate independently of the model itself.
As AI systems begin to move from assisting with security tasks to potentially performing them, organizations will need to account for the risks introduced by delegating these responsibilities. Maintaining visibility into how decisions are made and control over how actions are executed is likely to become more important as the window for direct human intervention narrows and the role of human expertise shifts toward oversight and guidance. This includes not only securing individual models but also ensuring the integrity of the broader AI supply chain and the systems through which models interact, collaborate, and evolve.
As these capabilities continue to evolve, success may depend not just on adopting AI-driven tools but on how effectively they are operationalized, combining automated discovery with human judgment, and ensuring that detection can translate into coordinated action and measurable risk reduction. In practice, this may require security approaches that extend beyond discovery and remediation to include greater visibility and control over how AI-driven actions are carried out in real-world environments. As autonomy increases, this also means treating runtime behavior as a primary security concern, ensuring that AI systems can be observed, governed, and controlled as they act.

Reflections on RSAC 2026: Moving Beyond Messaging and Sponsored Lists to Measurable AI Security
It was evident at RSAC Conference 2026 that AI security has firmly arrived as a top priority across the cybersecurity industry.
Nearly every vendor now positions themselves as an “AI security” provider. Many announced new capabilities, expanded messaging, or rebranded existing offerings to align with this shift. On the surface, this reflects positive momentum, recognizing that securing AI systems is critical as companies increasingly deploy AI and agents into production. However, a closer look reveals a more nuanced reality.
This rapid expansion has also driven a growing need for structure and shared understanding across the industry. Industry groups and communities have continued to grow, playing an important and necessary role by working to harness community expertise and provide CISOs with clearer frameworks, guidance, and shared understanding in a rapidly evolving space. This kind of industry coordination is critical as organizations seek common standards and practical ways to manage new risk categories. While well-intentioned, the vendor landscapes they publish can add to the confusion when the lists are created from self-assessment forms or sponsorships. This can make it more difficult for security leaders to distinguish between self-assessed capabilities vs. production-ready platforms, ultimately adding to the noise at a time when clarity and validation are most needed.
A Familiar Pattern: Strong Messaging, Limited Maturity
A consistent theme across RSAC was that many vendors are still early in their AI security journey. In many cases, solutions announced over the past year were presented again, often with updated language, broader claims, or expanded positioning. While this is typical of emerging markets, it highlights an important gap between market awareness and operational maturity.
Organizations evaluating AI security solutions should look beyond messaging and focus on things like evidence of real-world deployment, demonstrated effectiveness against adversarial techniques, and integration into production AI workflows. AI security is not a conceptual problem but an operational one.
The Expansion of “AI Security” as a Category
Another clear trend is the rapid expansion of vendors entering the space. Many traditional cybersecurity providers are extending existing capabilities, such as API security, identity, data loss prevention, or monitoring, into AI use cases. This is a natural evolution, and these controls can provide value at certain layers. However, AI systems introduce fundamentally new risk categories that extend beyond traditional security domains.
AI systems introduce a distinct set of challenges, including unpredictable model behavior and non-deterministic outputs, adversarial inputs such as prompt manipulation, risks within the model supply chain, including embedded threats, and the growing complexity of autonomous agent actions and decision-making. Together, these factors create a fundamentally different security landscape; one that cannot be adequately addressed by extending traditional tools, but instead requires specialized, purpose-built approaches designed specifically for how AI systems operate.
The Risk of Over-Simplification
One of the most common narratives at RSAC was that AI security can be addressed through relatively narrow control points, most often through guardrails, filtering, or policy enforcement. These controls are important. These controls are important, they help reduce risk and establish a baseline, but they are not sufficient on their own.
AI systems operate across a complex lifecycle, with risk present from training and data ingestion through model development and the supply chain, into deployment, runtime behavior, and integration with applications and agents. Focusing on just one of these layers can create gaps in coverage, especially as adversarial techniques continue to evolve.
In practice, effective AI security requires depth across multiple domains. This includes understanding how models behave, anticipating and testing against adversarial techniques, detecting and responding to threats in real time, and integrating security into the broader application and infrastructure stack.
As a result, many organizations are finding that AI security cannot simply be absorbed into existing tools or teams. It requires dedicated focus and specialized capability. Industry frameworks increasingly reflect this reality, recognizing that AI risk spans environmental, algorithmic, and output layers, each requiring its own controls and ongoing monitoring.
From Concept to Capability: What to Look For
As the market evolves, organizations should prioritize solutions that demonstrate purpose-built AI security capabilities rather than repurposed controls, along with coverage across the full AI lifecycle. Strong solutions also show continuous validation through red teaming and testing, the ability to detect and respond to adversarial activity in real time, and proven deployment in complex enterprise environments.
This becomes especially important as AI systems are embedded into high-impact workflows where failures can directly affect business outcomes. Protecting these systems requires consistent security across both development pipelines and runtime environments, ensuring coverage at scale as AI adoption grows.
The Path Forward: From Awareness to Execution
The growth of AI security as a category is a positive signal. It reflects both the importance of the challenge and the urgency felt across the industry. At the same time, the market is still early, and messaging often moves faster than real capability.
The next phase will be shaped by a shift toward measurable outcomes, demonstrated resilience against real adversaries, and security that is integrated into how systems operate, not added as an afterthought. RSAC 2026 highlighted both the opportunity and the work ahead. While there is clear alignment that AI systems must be secured, there is still progress to be made in turning that awareness into effective, production-ready solutions.
For organizations, this means evaluating AI security with the same rigor as any other critical domain, grounded in evidence, validated in real environments, and designed for how systems actually function. In practice, confidence comes from what works, not just how it’s described. We welcome and encourage that rigor, as those who spent time with us at RSAC can attest.

Securing AI Agents: The Questions That Actually Matter
At RSA this year, a familiar theme kept surfacing in conversations around AI:
Organizations are moving fast. Faster than their security strategies.
AI agents are no longer experimental. They’re being deployed into real environments, connected to tools, data, and infrastructure, and trusted to take action on behalf of users. And as that autonomy increases, so does the risk.
Because, unlike traditional systems, these agents don’t just follow predefined logic. They interpret, decide, and act. And that means they can be manipulated, misled, or simply make the wrong call.
So the question isn’t whether something will go wrong, but rather if you’ve accounted for it when it does.
Joshua Saxe recently outlined a framework for evaluating security-for-AI vendors, centered around three areas: deterministic controls, probabilistic guardrails, and monitoring and response. It’s a useful way to structure the conversation, but the real value lies in the questions beneath it, questions that get at whether a solution is designed for how AI systems actually behave.
Start With What Must Never Happen
The first and most important question is also the simplest:
What outcomes are unacceptable, no matter what the model does?
This is where many approaches to AI security break down. They assume the model will behave correctly, or that alignment and prompting will be enough to keep it on track. In practice, that assumption doesn’t hold. Models can be influenced. They can be attacked. And in some cases, they can fail in ways that are hard to predict.
That’s why security has to operate independently of the model’s reasoning.
At HiddenLayer, this is enforced through a policy engine that allows teams to define deterministic controls, rules that make certain actions impossible regardless of the model’s intent. That could mean blocking destructive operations, such as deleting infrastructure, preventing sensitive data from being accessed or exfiltrated, or stopping risky sequences of tool usage before they complete. These controls exist outside the agent itself, so even if the model is compromised, the boundaries still hold.
The goal isn’t to make the model perfect. It’s to ensure that certain failures can’t happen at all.
Then Ask: Who Has Tried to Break It?
Defining controls is one thing. Validating them is another.
A common pattern in this space is to rely on internal testing or controlled benchmarks. But AI systems don’t operate in controlled environments, and neither do attackers.
A more useful question is: who has actually tried to break these controls?
HiddenLayer’s approach has been to test under real pressure, running capture-the-flag challenges at events like Black Hat and DEF CON, where thousands of security researchers actively attempt to bypass protections. At the same time, an internal research team is continuously developing new attack techniques and using those findings to improve detection and enforcement.
That combination matters. It ensures the system is tested not just against known threats, but also against novel approaches that emerge as the space evolves.
Because in AI security, yesterday’s defenses don’t hold up for long.
Security Has to Adapt as Fast as the System
Even with strong controls, another challenge quickly emerges: flexibility.
AI systems don’t stay static. Teams iterate, expand capabilities, and push for more autonomy over time. If security controls can’t evolve alongside them, they either become bottlenecks or are bypassed entirely.
That’s why it’s important to understand how easily controls can be adjusted.
Rather than requiring rebuilds or engineering changes, controls should be configurable. Teams should be able to start in an observe-only mode, understand how agents behave, and then gradually enforce stricter policies as confidence grows. At the same time, different layers of control, organization-wide, project-specific, or even per-request, should allow for precision without sacrificing consistency.
This kind of flexibility ensures that security keeps pace with development rather than slowing it down.
Not Every Risk Can Be Eliminated
Even with deterministic controls in place, not everything can be prevented.
There will always be scenarios where risk has to be accepted, whether for usability, performance, or business reasons. The question then becomes how to manage that risk.
This is where probabilistic guardrails come in.
Rather than trying to block every possible attack, the goal shifts to making attacks visible, detectable, and ultimately containable. HiddenLayer approaches this by using multiple detection models that operate across different dimensions, rather than relying on a single classifier. If one model is bypassed, others still have the opportunity to identify the behavior.
These systems are continuously tested and retrained against new attack techniques, both from internal research and external validation efforts. The objective isn’t perfection, but resilience.
Because in practice, security isn’t about eliminating risk entirely. It’s about ensuring that when something goes wrong, it doesn’t go unnoticed.
Detection Only Works If It Happens Before Execution
One of the most critical examples of this is prompt injection.
Many solutions attempt to address prompt injection within the model itself, but this approach inherits the model's weaknesses. A more effective strategy is to detect malicious input before it ever reaches the agent.
HiddenLayer uses a purpose-built detection model that classifies inputs prior to execution, operating outside the agent’s reasoning process. This allows it to identify injection attempts without being susceptible to them and to stop them before any action is taken.
That distinction is important.
Once an agent executes a malicious instruction, the opportunity to prevent damage has already passed.
Visibility Isn’t Enough Without Enforcement
As AI systems scale, another reality becomes clear: they move faster than human response times.
This raises a practical question: can your team actually monitor and intervene in real time?
The answer, increasingly, is no. Not without automation.
That’s why enforcement needs to happen in line. Every prompt, tool call, and response should be inspected before execution, with policies applied immediately. Risky actions can be blocked, and high-risk workflows can automatically trigger checkpoints.
At the same time, visibility still matters. Security teams need full session-level context, integrations with existing tools like SIEMs, and the ability to trace behavior after the fact.
But visibility alone isn’t sufficient. Without real-time enforcement, detection becomes hindsight.
Coverage Is Where Most Strategies Break Down
Even strong controls and detection models can fail if they don’t apply everywhere.
AI environments are inherently fragmented. Agents can exist across frameworks, cloud platforms, and custom implementations. If security only covers part of that surface area, gaps emerge, and those gaps become the path of least resistance.
That’s why enforcement has to be layered.
Gateway-level controls can automatically discover and protect agents as they are deployed. SDK integrations extend coverage into specific frameworks. Cloud discovery ensures that assets across environments like AWS, Azure, and Databricks are continuously identified and brought under policy.
No single control point is sufficient on its own. The goal is comprehensive coverage, not partial visibility.
The Question Most People Avoid
Finally, there’s the question that tends to get overlooked:
What happens if something gets through?
Because eventually, something will.
When that happens, the priority is understanding and containment. Every interaction should be logged with full context, allowing teams to trace what occurred and identify similar behavior across the environment. From there, new protections should be deployable quickly, closing gaps before they can be exploited again.
What security solutions can’t do, however, is undo the impact entirely.
They can’t restore deleted data or reverse external actions. That’s why the focus has to be on limiting the blast radius, ensuring that failures are small enough to recover from.
Prevention and containment are what make recovery possible.
A Different Way to Think About Security
AI agents introduce a fundamentally different security challenge.
They aren’t static systems or predictable workflows. They are dynamic, adaptive, and capable of acting in ways that are difficult to anticipate.
Securing them requires a shift in mindset. It means defining what must never happen, managing the remaining risks, enforcing controls in real time, and assuming failures will occur.
Because they will.
The organizations that succeed with AI won’t be the ones that assume everything works as expected.
They’ll be the ones prepared for when it doesn’t.

The Hidden Risk of Agentic AI: What Happens Beyond the Prompt
As organizations adopt AI agents that can plan, reason, call tools, and execute multi-step tasks, the nature of AI security is changing.
AI is no longer confined to generating text or answering prompts. It is becoming operational actors inside the business, interacting with applications, accessing sensitive data, and taking action across workflows without human intervention. Each execution expands the potential blast radius. A single prompt can redirect an agent, trigger unsafe tool use, expose sensitive data, and cascade across systems in an execution chain — before security teams have visibility.
This shift introduces a new class of security risk. Attacks are no longer limited to manipulating model outputs. They can influence how an agent behaves during execution, leading to unintended tool usage, data exposure, or persistent compromise across sessions. In agentic systems, a single injected instruction can cascade through multiple steps, compounding impact as the agent continues to act.
According to HiddenLayer’s 2026 AI Threat Landscape Report, 1 in 8 AI breaches are now linked to agentic systems. Yet 31% of organizations cannot determine whether they’ve experienced one.
The root of the problem is a visibility gap.
Most AI security controls were designed for static interactions, and they remain essential. They inspect prompts and responses, enforce policies at the boundaries, and govern access to models.
But once an agent begins executing, those controls no longer provide visibility into what happens next. Security teams cannot see which tools are being called, what data is being accessed, or how a sequence of actions evolves over time.
In agentic environments, risk doesn’t replace the prompt layer. It extends beyond it. It emerges during execution, where decisions turn into actions across systems and workflows. Without visibility into runtime behavior, security teams are left blind to how autonomous systems operate and where they may be compromised.
To address this gap, HiddenLayer is extending its AI Runtime Protection module to cover agentic execution. These capabilities extend runtime protection beyond prompts and policies to secure what agents actually do — providing visibility, hunting and investigation, and detection and enforcement as autonomous systems operate.
Why Runtime Security Matters for Agentic AI
Agentic AI systems operate differently from traditional AI applications. Instead of producing a single response, they execute multi-step workflows that may involve:
- Calling external tools or APIs
- Accessing internal data sources
- Interacting with other agents or services
- Triggering downstream actions across systems
This means security teams must understand what agents are doing in real time, not just the prompt that initiated the interaction.
Bringing Visibility to Autonomous Execution
The next generation of AI runtime security enables security teams to observe and control how AI agents operate across complex workflows.
With these new capabilities, organizations can:
- Understand what actually happened
Reconstruct multi-step agent sessions to see how agents interact with tools, data, and other systems.
- Investigate and hunt across agent activity
Search and analyze agent workflows across sessions, execution paths, and tools to identify anomalous behavior and uncover emerging threats.
- Detect and stop agentic attack chains
Identify prompt injection, malicious tool sequences, and data exfiltration across multi-step execution and agent activity before they propagate across systems.
- Enforce runtime controls
Automatically block, redact, or detect unsafe agent actions based on real-time behavior and policies.
Together, these capabilities help organizations move from limited prompt-level inspection to full runtime visibility and control over autonomous execution.
Supporting the Next Phase of AI Adoption
HiddenLayer’s expanded runtime security capabilities integrate with agent gateways and frameworks, enabling organizations to deploy protections without rewriting applications or disrupting existing AI workflows.
Delivered as part of the HiddenLayer AI Security Platform, allowing organizations to gain immediate visibility into agent behavior and expand protections as their AI programs evolve.
As enterprises move toward autonomous AI systems, securing execution becomes a critical requirement.
What This Means for You
As organizations begin deploying AI agents that can call tools, access data, and execute multi-step workflows, security teams need visibility beyond the prompt. Traditional AI protections were designed for static interactions, not autonomous systems operating across enterprise environments.
Extending runtime protection to agent behavior enables organizations to observe how AI systems actually operate, detect risk as it emerges, and enforce controls in real time. As agentic AI adoption grows, securing the runtime layer will be essential to deploying these systems safely and confidently.

Why Autonomous AI Is the Next Great Attack Surface
Large language models (LLMs) excel at automating mundane tasks, but they have significant limitations. They struggle with accuracy, producing factual errors, reflecting biases from their training process, and generating hallucinations. They also have trouble with specialized knowledge, recent events, and contextual nuance, often delivering generic responses that miss the mark. Their lack of autonomy and need for constant guidance to complete tasks has given them a reputation of little more than sophisticated autocomplete tools.
The path toward true AI agency addresses these shortcomings in stages. Retrieval-Augmented Generation (RAG) systems pull in external, up-to-date information to improve accuracy and reduce hallucinations. Modern agentic systems go further, combining LLMs with frameworks for autonomous planning, reasoning, and execution.
The promise of AI agents is compelling: systems that can autonomously navigate complex tasks, make decisions, and deliver results with minimal human oversight. We are, by most reasonable measures, at the beginning of a new industrial revolution. Where previous waves of automation transformed manual and repetitive labor, this one is reshaping intelligent work itself, the kind that requires reasoning, judgment, and coordination across systems. AI agents sit at the heart of that shift.
But their autonomy cuts both ways. The very capabilities that make agents useful, their ability to access tools, retain memory, and act independently, are the same capabilities that introduce new and often unpredictable risks. An agent that can query your database and take action on the results is powerful when it works as intended, and potentially dangerous when it doesn't. As organizations race to deploy agentic systems, the central challenge isn't just building agents that can do more; it's ensuring they do so safely, reliably, and within boundaries we can trust.
What Makes an AI Agent?
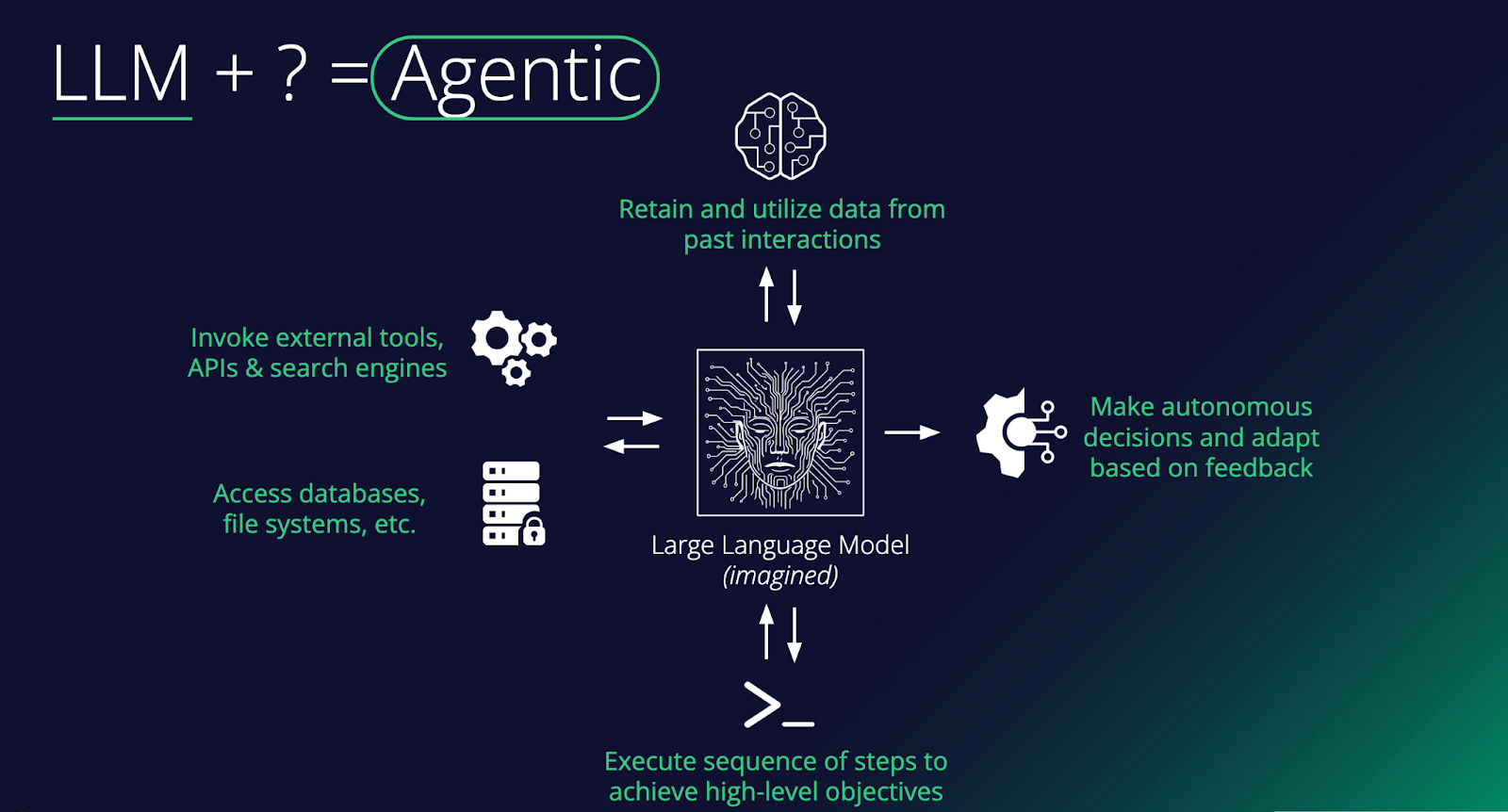
At its core, an agent is a large language model augmented with capabilities that enable it to do things in the world, not just generate text. As the diagram shows, the key ingredients include: memory to remember past interactions, access to external tools such as APIs and search engines, the ability to read and write to databases and file systems, and the ability to execute multi-step sequences toward a goal. Stack these together, and you turn a passive text predictor into something that can plan, act, and learn.
The critical distinguishing feature of an agent is autonomy. Rather than simply responding to a single prompt, an agent can make decisions, take actions in its environment, observe the results, and adapt based on feedback, all in service of completing a broader objective. For example, an agent asked to "book the cheapest flight to Tokyo next week" might search for flights, compare options across multiple sites, check your calendar for conflicts, and proceed to book, executing a whole chain of reasoning and tool use without needing step-by-step human instruction. This loop of planning, acting, and adapting is what separates agents from standard chatbot interactions.
In the enterprise, agents are quickly moving from novelty to necessity. Companies are deploying them to handle complex workflows that previously required significant human coordination, things like processing invoices end-to-end, triaging customer support tickets across multiple systems, or orchestrating data pipelines. The real value comes when agents are connected to a company's internal tools and data sources, allowing them to operate within existing infrastructure rather than alongside it. As these systems mature, the focus is shifting from "can an agent do this task?" to "how do we reliably govern, monitor, and scale agents across the organization?"
The Evolution of Prompt Injection
When prompt injection first emerged, it was treated as a curiosity. Researchers tricked chatbots into ignoring their system prompts, producing funny or embarrassing outputs that made for good social media posts. That era is over. Prompt injection has matured into a legitimate delivery mechanism for real attacks, and the reason is simple: the targets have changed. Adversaries are no longer injecting prompts into chatbots that can only generate text. We're injecting them into agents that can execute code, call APIs, access databases, browse the web, and deploy tools. A successful prompt injection against a browsing agent can lead to data exfiltration. Against an enterprise agent with access to internal systems, it functions as an insider threat. Against a coding agent, it can result in malware being written and deployed without a human ever reviewing it. Prompt injection is no longer about making an AI say something it shouldn't. It's about making an AI take an action that it shouldn't, and the blast radius grows with every new capability we hand these systems.
Et Tu, Jarvis?
Nowhere is this more visible than in the rise of personal agents. Tony Stark's Jarvis in the Marvel Cinematic Universe set the bar for a personal AI assistant that manages your life, automates complex tasks, monitors your systems, and never sleeps. But what if Jarvis wasn't always on his side? OpenClaw brought that vision closer to reality than anything before it. Formerly known as Moltbot and ClawdBot, this open-source autonomous AI assistant exploded onto the scene in late 2025, amassing over 100,000 GitHub stars and becoming one of the fastest-growing open-source projects in history. It offered a "24/7 personal assistant" that could manage calendars, automate browsing, run system commands, and integrate with WhatsApp, Telegram, and Discord, all from your local machine. Around it, an entire ecosystem materialized almost overnight: Moltbook, a Reddit-style social network exclusively for AI agents with over 1.5 million registered bots, and ClawHub, a repository of skills and plugins.
The problem? The security story was almost nonexistent. Our research demonstrated that a simple indirect prompt injection, hidden in a webpage, could achieve full remote code execution, install a persistent backdoor via OpenClaw's heartbeat system, and establish an attacker-controlled command-and-control server. Tools ran without user approval, secrets were stored in plaintext, and the agent's own system prompt was modifiable by the agent itself. ClawHub lacked any mechanisms to distinguish legitimate skills from malicious ones, and sure enough, malicious skill files distributing macOS and Windows infostealers soon appeared. Moltbook's own backing database was found wide open with no access controls, meaning anyone could spoof any agent on the platform. What was designed as an ecosystem for autonomous AI assistants had inadvertently become near-perfect infrastructure for a distributed botnet.
The Agentic Supply Chain: A New Attack Surface
OpenClaw's ecosystem problems aren't unique to OpenClaw. The way agents discover, install, and depend on third-party skills and tools is creating the same supply chain risks that have plagued software package managers for years, just with higher stakes. New protocols like MCP (Model Context Protocol) are enabling agents to plug into external tools and data sources in a standardized way, and around them, entire ecosystems are emerging. Skills marketplaces, agent directories, and even social media-style platforms like Smithery are popping up as hubs for sharing and discovering agent capabilities. It's exciting, but it's also a story we've seen before.
Think npm, PyPI, or Docker Hub. These platforms revolutionized software development while simultaneously creating sprawling supply chains in which a single compromised package could ripple across thousands of applications. Agentic ecosystems are heading down the same path, arguably with higher stakes. When your agent connects to a third-party MCP server or installs a community-built skill, you're not only importing code, but also granting access to systems that can take autonomous action. Every external data source an agent touches, whether browsing the web, calling an API, or pulling from a third-party tool, is potentially untrusted input. And unlike a traditional application where bad data might cause a display error, in an agentic system, it can influence decisions, trigger actions, and cascade through workflows. We're building new dependency chains, and with them, new vectors for attack that the industry is only beginning to understand.
Shadow Agents, Shadow Employees
External attackers are one part of the equation. Sometimes the threat comes from within. We've already seen the rise of shadow IT and shadow AI, where employees adopt tools and models outside of approved channels. Agents take this a step further. It's no longer just an unauthorized chatbot answering questions; it's an unauthorized agent with access to company systems, making decisions and taking actions autonomously. At a certain point, these shadow tools become more like shadow employees, operating with real agency within your organization but without the oversight, onboarding, or governance you'd apply to an actual hire. They're harder to detect, harder to govern, and carry far more risk than a rogue spreadsheet or an unsanctioned SaaS subscription ever did. The threat model here is different from a compromised account or a disgruntled employee. Even when these agents are on IT's radar, the risk of an autonomous system quietly operating in an unforeseen manner across company infrastructure is easy to underestimate, as the BodySnatcher vulnerability demonstrated.
An Agent Will Do What It's Told
Suppose an attacker sits halfway across the globe with no credentials, no prior access, and no insider knowledge. Just a target's email address. They connect to a Virtual Agent API using a hardcoded credential identical across every customer environment. They impersonate an administrator, bypassing MFA and SSO entirely. They engage a prebuilt AI agent and instruct it to create a new account with full admin privileges. Persistent, privileged access to one of the most sensitive platforms in enterprise IT, achieved with nothing more than an email. This is BodySnatcher, a vulnerability discovered by AppOmni in January 2026 and described as one of the most severe AI-driven security flaws uncovered to date. Hardcoded credentials and weak identity logic made the initial access possible, but it was the agentic capabilities that turned a misconfiguration into a full platform takeover. It's a clear example of how agentic AI can amplify traditional exploitation techniques into something far more damaging.
Conclusions
Agents represent a fundamental shift in how individuals and organizations interact with AI. Autonomous systems with access to sensitive data, critical infrastructure, and the ability to act on both - how long before autonomous systems subsume critical infrastructure itself? As we've explored in this blog, that shift introduces risk at every level: from the supply chains that power agent ecosystems, to the prompt injection techniques that have evolved to exploit them, to the shadow agents operating inside organizations without any security oversight.
The challenge for security teams is that existing frameworks and controls were not designed with autonomous, tool-using AI systems in mind. The questions that matter now are ones many organizations haven't yet had to ask. How do you govern a non-human actor? How do you monitor a chain of autonomous decisions across multiple systems? How do you secure a supply chain built on community-contributed skills and open protocols?
This blog has focused on framing the problem. In part two, we'll go deeper into the technical details. We'll examine specific attack techniques targeting agentic systems, walk through real exploit chains, and discuss the defensive strategies and architectural decisions that can help organizations deploy agents without inheriting unacceptable risk.

Understand AI Security, Clearly Defined
Explore our glossary to get clear, practical definitions of the terms shaping AI security, governance, and risk management.